
 [PGGAN] Progressive Growing of GANs for Improved Quality, Stability, and Varation
[PGGAN] Progressive Growing of GANs for Improved Quality, Stability, and Varation
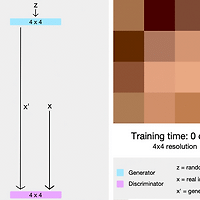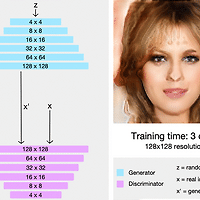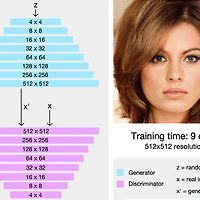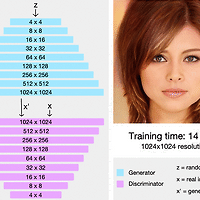
1. Abstract 1-1. Problem PGGAN(Progressive Growing of GANs)은 2017년도에 나온 Nvidia에서 나온 논문이고 발표 당시 큰 이슈를 받았다고 한다. 그 이유는 그 전까지 GAN들은 고해상도(High resolution) 이미지를 만드는것이 매우 힘들었는데 이 논문이 새로운 접근 방법으로 고해상도 이미지 생성하는 것을 해결했다. 일반적인 GAN으로 고해상도 이미지를 만든다고 한다면, 아래와 같은 문제들이 발생을 할 것 이다. - 고해상도 이미지를 만드는 것은 매우 어려운 일이다. 그 이유는, High Resolution 일수록 Discriminator는 Generator가 생성한 Image가 Fake Image인지 아닌지를 구분하기가 쉬워지기 때문이다. - ..
 [AnoGAN] Unsupervised Anomaly Detection with GAN 정리
[AnoGAN] Unsupervised Anomaly Detection with GAN 정리
Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide MArker Discovery 일명 "AnoGAN"에 대한 paper을 읽고 정리한 공부자료 입니다. 기본개념 GAN이란? GAN의 학습 과정은, Discriminator가 Real과 Fake를 잘 맞추도록 훈련을 한 다음, Generator가 만들어낸 Fake image가 Discriminator에서 Real로 나오도록 하는 학습 과정입니다. DCGAN - CNN vs MLP MLP : 3차원 데이터를 1개의 Vector로 풀어서 인식한다. 그로인해 단점은 이미지의 위치 정보를 무시하게 된다(feature loss발생) CNN : 3차원 데이터 입력을 그대로 사용한다..
GAN 중에서 가장 기본적인 "Generative Adversarial Network"에 대해 논문을 읽고 참고자료를 본 후 정리한 공부자료 입니다. + 정리하다가 Autoencoder와 VAE 개념을 먼저 알아야 GAN을 이해하기 쉽다는 생각이 들어서 추후에 정리하도록 하겠습니다. GAN을 하기 전에 기본 개념 1. Supervised Learning Supervised Learning에 대한 내용은 자세하게 설명은 안하겠습니다. 우리가 흔히 알고있는 Supervised Learning은 "model이 학습을 할 때 Label data가 존재해야 한다" 라는 것 입니다. 그래서 보통 input data를 알맞은 class로 분류(classification)을 해주는 거로 알고 있습니다. 위에서 보이는 ..
 (Tensorflow_eager)Mnist와 AlexNet을 이용한 CNN
(Tensorflow_eager)Mnist와 AlexNet을 이용한 CNN
목표 Mnist data와 AlexNet 구조를 이용해서 Convolutional Neural Network기반으로 10개의 숫자 손글씨를 classification하것이다. 여기서 우리는, Tensorflow의 Session()모드로 사용 안하고 Eager()모드를 사용해서 코드를 구성해보도록 하겠습니다 ※eager mode : tf.2.0 version부터는 Session() 방식보단 Eager 방식을 쓰는 것을 권장한다고 합니다. 1. Input Module 2. enable eager 1) tf.enable_eager_execution() eager mode를 사용하려면 이 내용을 작성해주어야 한다. 그러면, tensorflow의 placeholder와 Session() 구문을 사용 못하게 된다...
 [Kaggle] Attention on Pretrained-VGG16 for Bone Age_전처리 과정
[Kaggle] Attention on Pretrained-VGG16 for Bone Age_전처리 과정
목표 BoneAge Project에 관련해서, original kernel 커널을 따라해보고, 그 것을 하나하나 설명한 뒤, 이 커털을 응용해서 제가 스스로 코드를 다른 방식으로 짜보는 것 입니다. original kaggle Kernel : https://www.kaggle.com/kmader/attention-on-pretrained-vgg16-for-bone-age ※버전 문제에 관련해서 코드 실행이 안되는 부분은 커스텀해서 수정한 부분도 있으니 참고 바랍니다. 1. import module 1) ImageDataGenerator Keras의 클래스이며, 이미지 파일을 쉽게 학습을 시킬 수 있는 클래스이다. 해당 클래스로 데이터 증식(data augmentation)을 할 수 있다. 의료AI에서는 ..
해당 글은 개인적으로 공부한 내용과 '김태영님의 블로그'를 참고한 글 입니다. 학습 문제와 해답지를 함께 제공을 하고(코드상에선 x와 y) 문제를 푼 뒤 정답지를 보며 맞는지 틀린지 확인하는 과정을 학습이라고 부른다. 평가 문제만 주고 풀게한 뒤, 그 문제가 맞는지 틀린지 점수(Score)만 계산하는 것. Validation Set 학생(모델)들의 학습 방법을 Validation set으로 평가해볼 수 있다. 그래서 Hyper-Parameter(공부방법)을 변경해가면서 학생(모델)에게 알맞은 공부 방법이 무엇인지 알아낼 수 있다. Hyper Parameter는 학습을 하면서 적절한 값을 찾아내야 한다. UnderFitting(언더피팅) 학습이 덜 상태를 의미하며 이는 학습을 더 하면 성능이 더 높아질 가..
 ch04. 신경망 학습(밑바닥부터 시작하는 딥러닝)
ch04. 신경망 학습(밑바닥부터 시작하는 딥러닝)
신경망 학습의 전체 그림 1단계) 미니배치(Mini-Batch) training data중 일부를 가지고 와서 배치화 시키는 작업이다. 미니배치의 목표는, 손실함수(cost function = loss function)값을 줄이는 것이 목표이다. 2단계) 기울기 산출 미니배치의 cost function 값을 줄이기 위해 각 가중치 매개변수(weight)의 기울기를 구한다. 기울기는, cost function의 값을 가장 작게 하는 방향을 제시하는 역할. 3단계) 매개변수 갱신 weight를 기울기 방향으로 아주 조금씩 갱신해준다. 4단계) 반복 1 ~ 3단계 과정을 계속 반복한다. 여기까지는 '밑바닥부터 시작하는 딥러닝'에 대한 내용을 작성한 것 입니다. 이제부턴 연구실에서 책 세미나 한 내용을 다시 혼..