
티스토리 뷰
목표
Mnist data와 AlexNet 구조를 이용해서 Convolutional Neural Network기반으로 10개의 숫자 손글씨를 classification하것이다. 여기서 우리는, Tensorflow의 Session()모드로 사용 안하고 Eager()모드를 사용해서 코드를 구성해보도록 하겠습니다
※eager mode : tf.2.0 version부터는 Session() 방식보단 Eager 방식을 쓰는 것을 권장한다고 합니다.
1. Input Module
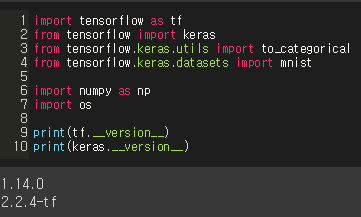
2. enable eager

1) tf.enable_eager_execution()
eager mode를 사용하려면 이 내용을 작성해주어야 한다.
그러면, tensorflow의 placeholder와 Session() 구문을 사용 못하게 된다.(사용해보면 error가 발생)
3. Parameter Setting
learning rate = 0.001
training_epochs = 90
batch_size = 64
display_step = 20
4. load data
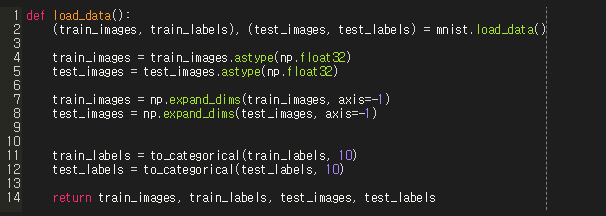
위와 같이, 맨 처음 mnist_load 데이터를 불러오면 shape이 (N, 28, 28) 형태일 것이다. 이것을 numpy형태로 변환시켜주고, np.expand_dims를 사용해서 차원을 하나 늘려준다.
5. Data Pipeline
data pipeline이란, data set을 load하고, batch_size만큼 가져와서 Network(AlexNet)에 공급해 주는 역할을 한다. 여기서는 tf.data를 사용해서 구성을 해볼것이다.

train_dataset과 test_dataset을 출력해보면 아래와 같이 출력된다.

6. Network
1) Function형태로 Network 정의
1-1) AlexNet이란?

paper상의 AlexNet의 구조는 5개의 Convolution layer, 3개의 Fully connected layer로 이루어져 있으며 마지막에 softmax를 사용해서 1000개의 class를 classification한다.

위에서 보면 알겠지만, input image의 크기가 244x244x3인 RGB 형태인것을 볼 수 있다. 그래서 Network 내부 파라미터 값들도 해당 이미지 크기에 맞게 구성이 되어있다. 그러나 mnist data는 28x28의 gray scale 이미지 이고, 아무런 변형 없이 paper 상의 AlexNet구조를 사용하면 error가 발생하게 된다. 따라서 AlexNet의 특징들을 그대로 가져와서 입력데이터 28x28x1에 맞게 변형을 해줘야 한다.
1-2) Actication을 ReLU로 사용.
간단하게 요약해보자면, Sidmoid()를 사용하게 되면 gradient가 0에 가까워져서 "Vanishing Gradient"현상이 발생하게 된다. 그래서 이 현상을 막고자 ReLU를 많이 사용하는데, Relu를 사용하면 Vanishing Gradient현상을 막을 수 있다.
SigMoid의 단점.
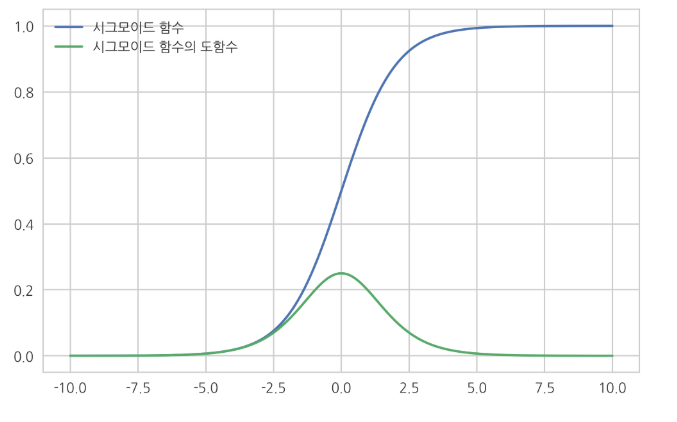
Net(망)이 깊어지게 되면, 매우 작은 gradient가 여러번 곱해지게 된다. sigmoid 특성상 gradient가 점점 0에 가까워지면서 Network에 전달할 Gradient가 없어지게 된다. 이런 현상이 Vanishing Gradient 현상이다.
따라서, Sidmoid를 사용해서 Net이 깊어지면(deep해지면) vanishing gradient 현상이 발생되서 학습이 잘 안이루어 진다.
※ 용어 정리
loss = grouond truth - output
gradient : Backpropagation으로 전달 된 loss를 미분한 것
Backpropagation : loss를 미분한 것이며, Network를 학습시킴.
1-3) Local Response Normalization
AlexNet 논문에 의하면 "sidmoid나 tanh를 사용하는것 보다 ReLU를 사용하면 학습 속도를 늘릴 수 있다"라고 나와 있다. sidmoid나 tanh를 사용할때는, overfitting을 피하기 위해 일반적으로 입력단에서 Normalization을 사용한다.
예를 들면, images는 픽셀이니 0 ~ 255의 값으로 구성이 되어있다. 이것을 255.0으로 나눠 0 ~ 1의 range를 갖도록 조정을 해준다.(
그러나, AlexNet 논문에서는, ReLU를 사용한다, ReLU를 사용하면 입력 단에서 굳이 Normalization을 해줄 필요가 없다는 장점이 있다.(해주고 싶으면 해도 된다.) 그래서 AlexNet에서는, feature maps 부분에서 Normalization을 시켜주므로서 ReLU 특성 상, 양수 방향으로 무한히 커지므로서 너무 커지는 것을 방지하기 위해 Feature maps 단에서 normalization을 해준다.
2) 코드로 구현
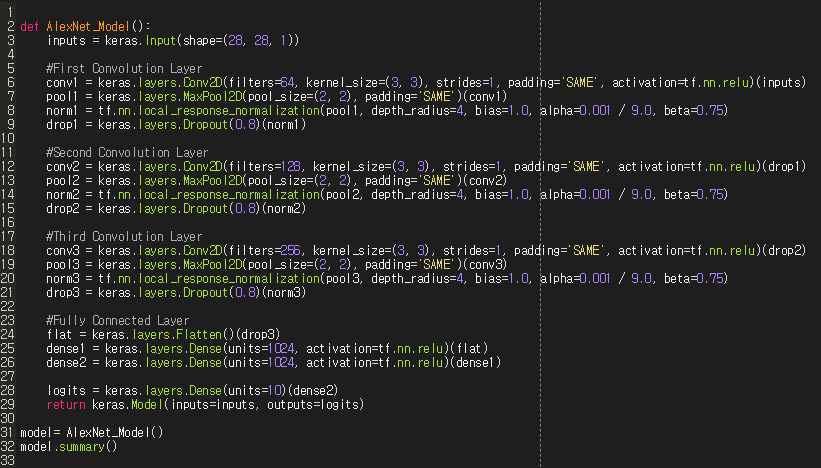
tensorflow의 eager mode로 코드를 작성할때 가장 좋은 방법은, Sequential이나, Function 형태로 Model을 구성하는게 아니라, Class로 짜주어서 subclassing 방법으로 작성을 하는게 나중에 custom할때 편하다고 한다. 그럼에도 불구하고 여기서 function형태로 작성을 해준 이유는, keras에서 local_response_normalization 함수가 사라졌기 때문이다. 그래서 이 함수의 수식을 그대로 하나하나 수작업으로 구성해서 할까도 생각을 해보았는데, tf.nn 함수에는 아직 있는것을 발견하고 fucntion으로 코드를 짜서 keras.layers와 tf.nn 함수로 Network를 구성해보았다.
7. Optimizer
Optimizer란, gradient를 이용해서 weight를 update하는 부분이다.

8. 훈련 결과

훈련 결과를 보면 AlexNet은 Data Augmentation을 시켜줬다고 하지만, mnist는 굳이 그럴 필요가 없을거 같아서 augmentation을 안하고 training을 해보았는데 accuracy가 잘 나오는 것을 확인할 수 있다.
자세한 코드는 Github를 정리하는 대로 github 주소를 공유하도록 하겠습니다.
'Python > 머신러닝&딥러닝' 카테고리의 다른 글
| [AnoGAN] Unsupervised Anomaly Detection with GAN 정리 (0) | 2019.11.05 |
|---|---|
| [GAN] Generative Adversarial Network 정리 (0) | 2019.10.17 |
| [Kaggle] Attention on Pretrained-VGG16 for Bone Age_전처리 과정 (1) | 2019.05.19 |
| 딥러닝 필수 기본 개념 (0) | 2019.05.19 |
| Ch02. 퍼셉트론(밑바닥부터 시작하는 딥러닝) (1) | 2019.04.12 |

