
티스토리 뷰
GAN 중에서 가장 기본적인 "Generative Adversarial Network"에 대해 논문을 읽고 참고자료를 본 후 정리한 공부자료 입니다.
+ 정리하다가 Autoencoder와 VAE 개념을 먼저 알아야 GAN을 이해하기 쉽다는 생각이 들어서 추후에 정리하도록 하겠습니다.
GAN을 하기 전에 기본 개념
1. Supervised Learning
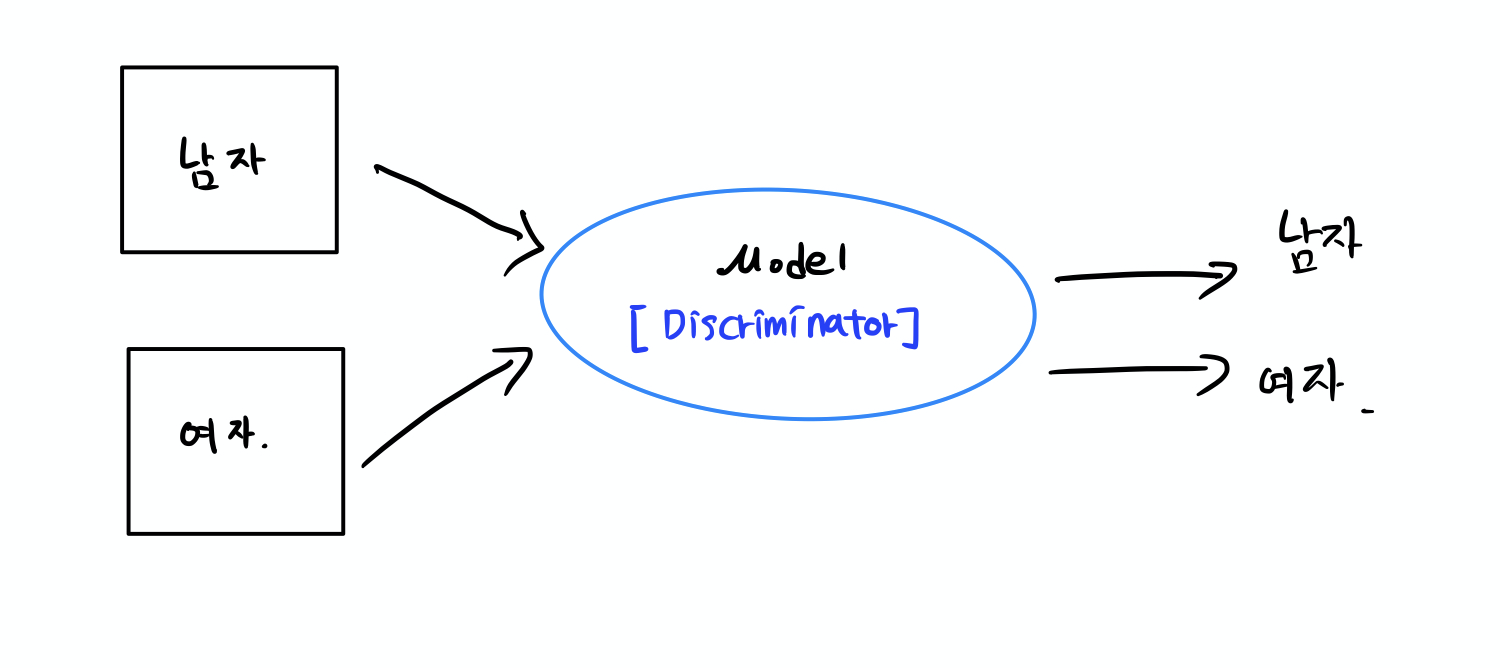
Supervised Learning에 대한 내용은 자세하게 설명은 안하겠습니다.
우리가 흔히 알고있는 Supervised Learning은 "model이 학습을 할 때 Label data가 존재해야 한다" 라는 것 입니다. 그래서 보통 input data를 알맞은 class로 분류(classification)을 해주는 거로 알고 있습니다. 위에서 보이는 supervised는 binary classification을 간단하게 그린 그림 입니다. 남자 이미지 데이터가 들어오면 남자 라고 정답을 말하는 쪽으로 학습을 하고, 여자 이미지 데이터가 들어오면 여자라고 말을 해주는 쪽으로 학습을 진행을 합니다.
GAN에서 "Discriminator"라는 개념이 있습니다. 다른 블로그에서 잘 정리가 되어있지만, GAN의 기본을 설명할때 흔히 경찰과 도둑의 예를 들게 됩니다. 경찰 = Discriminator라 비유를 하고 위조지폐인지 아닌지 검사하는 역할을 하게 됩니다. 도둑 = Generative라 비유를 하고, 위조지폐를 만들어서 이 위조지폐를 진짜 지폐화 비슷하게 만들어내는 역할을 합니다. 흔히 딥러닝에서는 "학습"이라고 하는 과정이 존재합니다. 이 학습이라는 과정을 직관적인 예를 들어보겠습니다.
도둑(Generative)이 신나게 위조지폐를 생성해서 가게에 물건을 사러 갔습니다. 근데 그 가게에 매장 직원이 경찰이였습니다. 이 경찰(Discriminator)이 위조지폐인것을 발견하고 도둑을 감옥에 집어 넣습니다. 그럼 그 도둑은 이전보다 더 진짜 지폐랑 동일하게 보이도록 출소 후에 위조지폐를 만들 계획을 세우고 위조지폐를 만들게 됩니다....... 이런 과정을 계속 반복하게 되며 이를 "학습"이라고 합니다. 결국, 언젠가는 사람 눈으로 볼때 진짜 지폐와 위조 지폐를 구분 못하는 경지가게 가게 됩니다.
2. Unsupervised Learning
비지도학습이라고 불리는 학습 방법입니다. 이 학습 방법의 특징은 Label데이터 즉, 정답이 없습니다. GAN이랑 비교를 하자면 Generative(도둑)이라고 할 수 있습니다.
Unsupervised Learning의 목적은, training data의 distribution을 학습 하는게 목표입니다.

GAN의 개념
1. Probability Distribution (확률분포)
wikipidia에서 나온 사전적인 정의는, 어떤 사건(event)에 어느 정도 확률이 할당되었는지 묘사한 정보를 확률분포(probability distribution)이라고 한다. 즉, 쉽게 이해하기 위해서 '주사위를 6번 굴렸을때 각 숫자가 얼마나 나올지에 대한 확률'이라고 생각하면 될거 같다.
이제 GAN 입장에서의 Probability Distribution을 생각을 해보자. 안경을 낀 남자 이미지, 안경을 안낀 여자의 이미지, 금발인 여자의 이미지 지. 이런식으로 데이터를 가지고 있다고 생각을 해보자. 그 특징을 나타내는 feature들의 vector값의 분포가 아래 그림과 같이 보여지게 된다.

그러면 이제 GAN에서 Fake image를 생성하는 Generative Model의 목표는 아래와 같다.
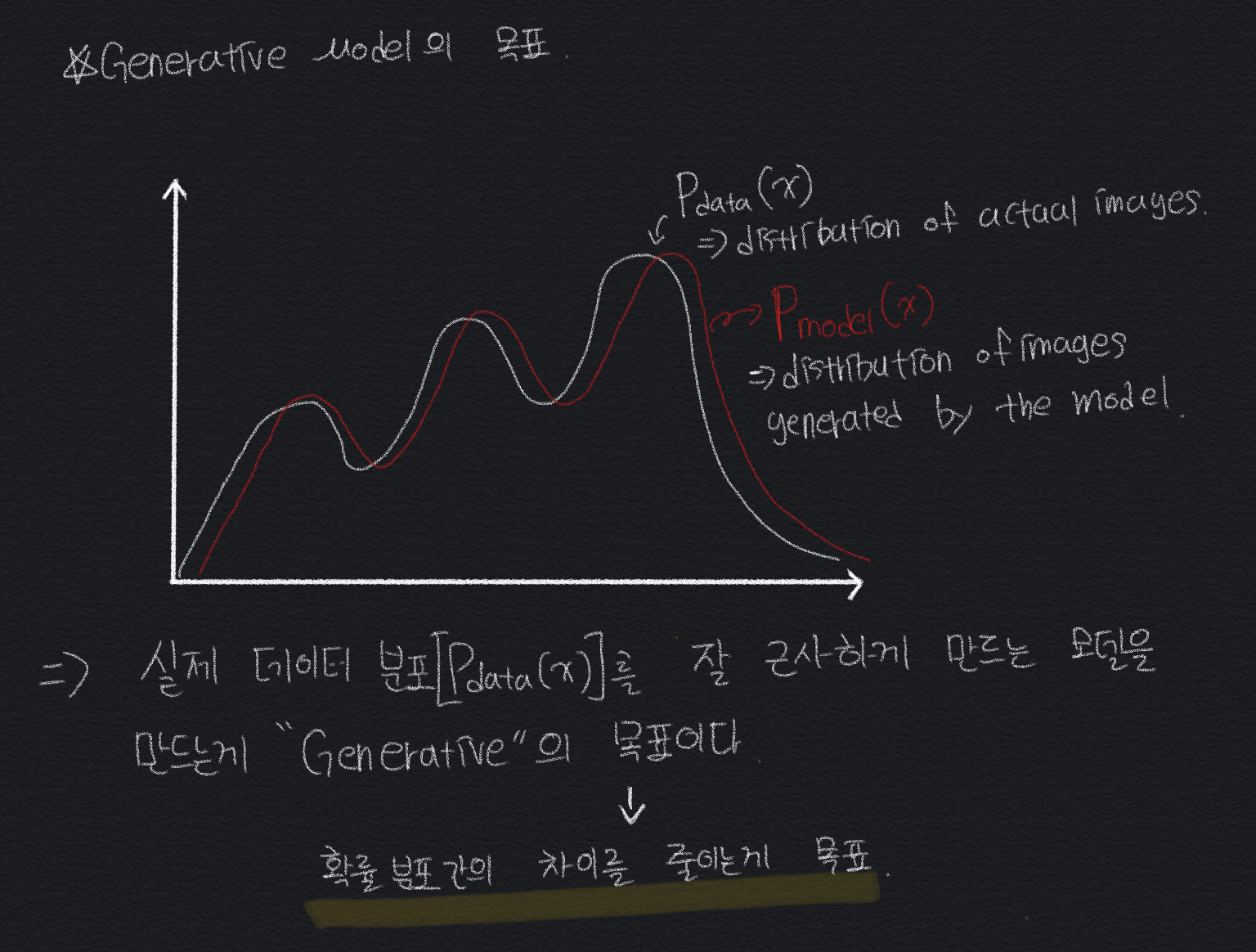
다시 정리를 하자면, 실제 Real Image에 대한 Data Distribution이 있으면, Generative model은 실제와 비슷한 Fake Image를 만들어내야 하니까 최대한 Distribution of actual images와 근사하게 만드는 모델을 만드는게 Generative의 목표이다.
2. GAN의 동작 원리
Discriminator Model 학습
순서 1. Discriminator model에 Real Image를 진짜(True)라고 먼저 학습을 시킨다.

순서 2. Discriminator mode에 Fake Image를 가짜(False)라고 먼저 학습을 한다.

이렇게 하는과정은 Binary classification이라고 볼 수 있어서 보통 마지막 output단에 sigmoid function을 두어서 0.5를 기준으로 True, False를 구분한다.
Generator Model 학습
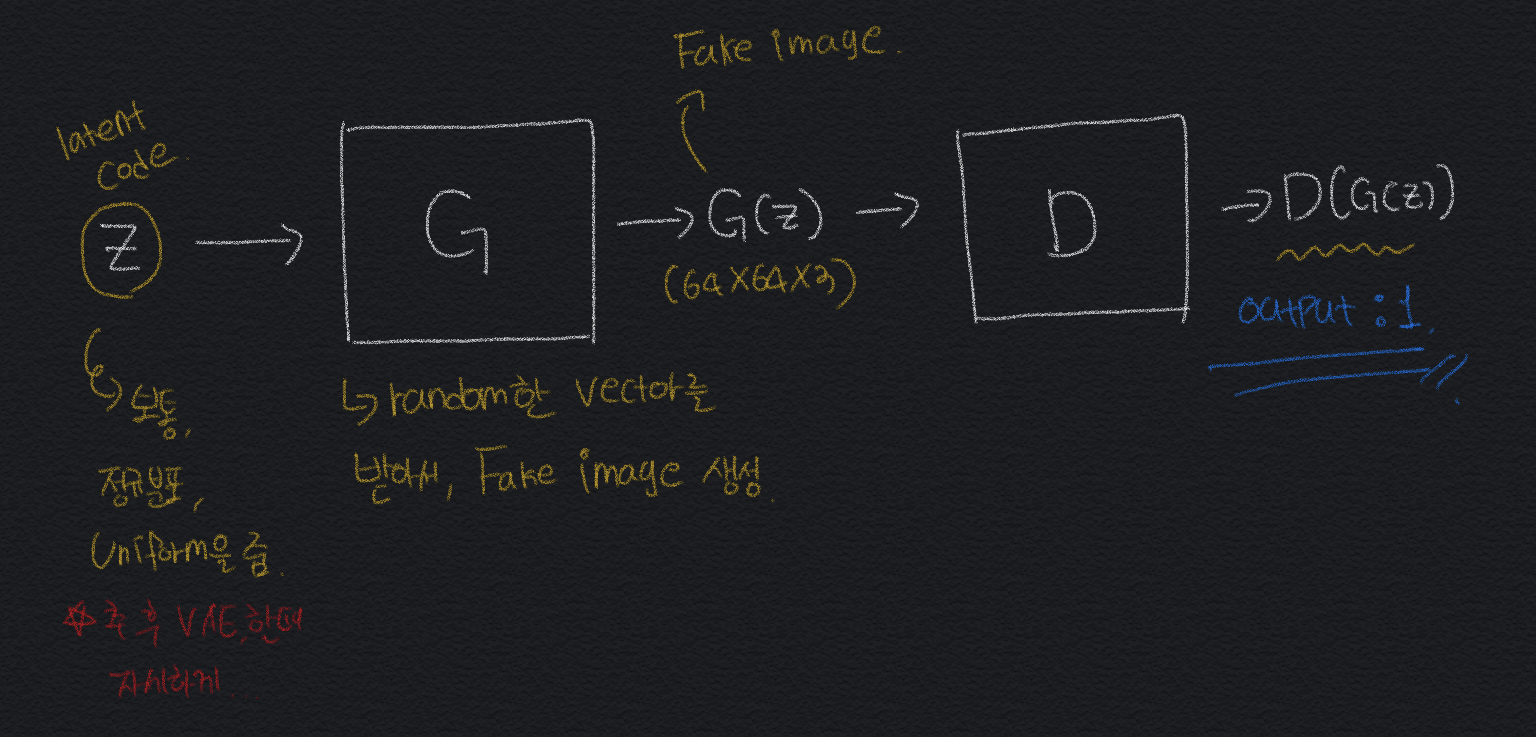
Fake Image를 생성해서 D가 output 결과를 1(True)가 나오도록 계속 반복적으로 Training을 해주는 방식이다.
수식으로 알아보는 GAN의 흐름
위에서 그림으로 직관적으로 알아본 GAN에 내용을 수식으로 알아보면 아래와 같다.

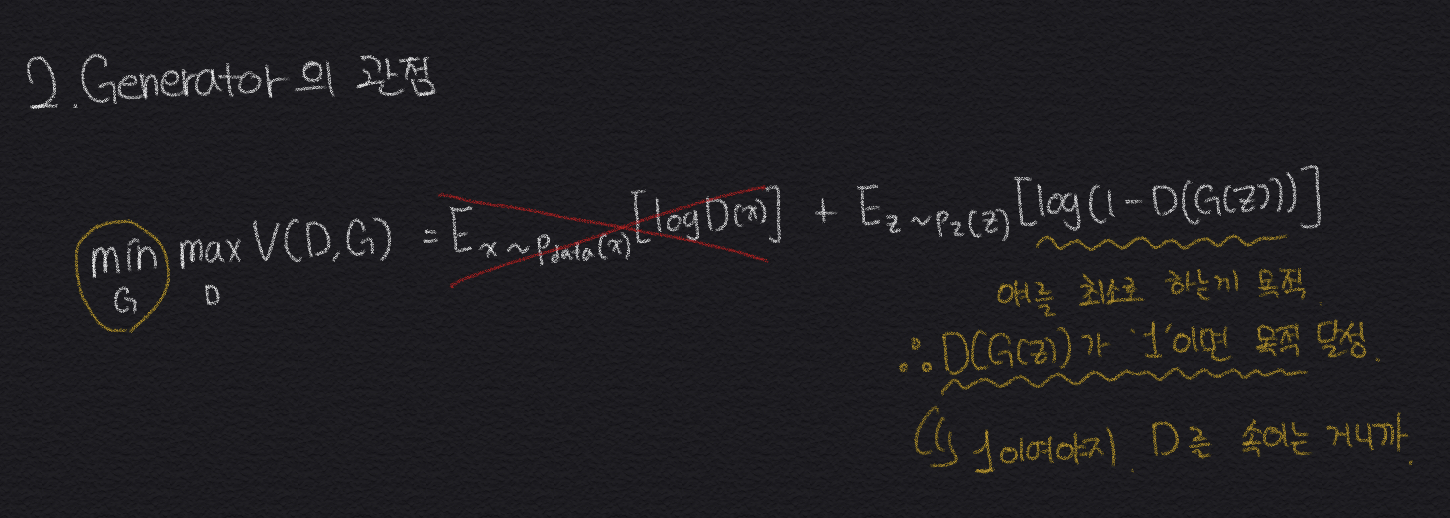
그리고 추가적으로 여기서 사용되는 LOSS Function은, "Binary Cross Entropy Loss"를 사용하며, 수식은
(h(x), y) = -ylogh(x) - (1 - y)log(1-h(x)) 이다. 위에 수식으로 GAN을 알아본거랑 동일한것을 알 수 있다.
'Python > 머신러닝&딥러닝' 카테고리의 다른 글
| [PGGAN] Progressive Growing of GANs for Improved Quality, Stability, and Varation (2) | 2019.12.20 |
|---|---|
| [AnoGAN] Unsupervised Anomaly Detection with GAN 정리 (0) | 2019.11.05 |
| (Tensorflow_eager)Mnist와 AlexNet을 이용한 CNN (0) | 2019.07.21 |
| [Kaggle] Attention on Pretrained-VGG16 for Bone Age_전처리 과정 (1) | 2019.05.19 |
| 딥러닝 필수 기본 개념 (0) | 2019.05.19 |



