
티스토리 뷰
[Kaggle] Attention on Pretrained-VGG16 for Bone Age_전처리 과정
Waterbottle 2019. 5. 19. 21:09목표
BoneAge Project에 관련해서, original kernel 커널을 따라해보고, 그 것을 하나하나 설명한 뒤, 이 커털을 응용해서 제가 스스로 코드를 다른 방식으로 짜보는 것 입니다.
original kaggle Kernel : https://www.kaggle.com/kmader/attention-on-pretrained-vgg16-for-bone-age
※버전 문제에 관련해서 코드 실행이 안되는 부분은 커스텀해서 수정한 부분도 있으니 참고 바랍니다.
1. import module

1) ImageDataGenerator
Keras의 클래스이며, 이미지 파일을 쉽게 학습을 시킬 수 있는 클래스이다. 해당 클래스로 데이터 증식(data augmentation)을 할 수 있다. 의료AI에서는 다른 분야와 다르게 데이터가 한정적이다. 인공지능의 핵심은 질 좋은 데이터양이다. 따라서 ImageDataGenerator클래스를 사용해서 Data augmentation을 진행한다.
2. Data Preprocessing
1) 엑셀 데이터와 실제 이미지 데이터 비교
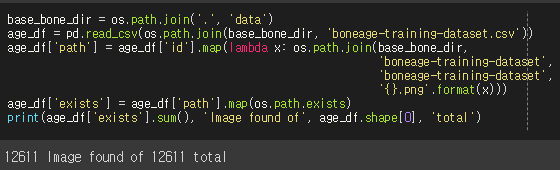
현재 해당 프로젝트에는 'csv'파일과 'Image'파일이 주어진다. csv파일에는 각 x-ray 이미지에 대한 'id', 'boneage', 'male' 이 적혀있다. 그래서, 엑셀에 정리된 자료와, 실제 이미지 데이터를 비교해가면서 결측값이 있는지 확인하는 작업이다. 그리고 그 경로와 결측값인 'path'와 'exists'들을 dataframe에 적용시켜둔다.
- lambda()함수,
lambda()는, 하나하나씩 순차적으로 밀어내기 방식이다. 이 의미를 기억하고 해석을 해보자면, os.path.join()에 있는 내용을 x에 저장해준다. 그래서 하나하나씩 순처적으로 'path'에 저장이 된다.
- 공부하다가 아게된점!
--> age_df['exists']를 찍어보면 True와 False로 나온다. 근데 이 값들을 .sum()를 사용하게되면 True인 값의 합이 수치적으로 나오게 된다는것을 알게 되었다.
2) 성별 표시
csv파일에 보명 'male' colum에서 True와 False로 볼 수 있다. 이제 이것을 우리가 아는 'mela'과 'female'로 바꾸어 줄 것 이다. 코드는 아래와 같다.
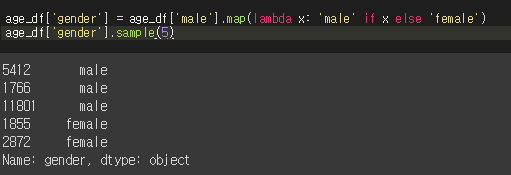
map()함수는, 한꺼번에 일괄적으로 묶어서 연산을 하겠다는 의미이다.
따라서, 해석을 해보자면
- age_df['male']에 있는 열(colum)에서 map() 함수를 이용해서 해당 연산을 묶어서 처리는 과정이다.
- age_df['male']값이 True와 False로 정리가 되어있다. 그래서 True와 False값이 lambda 안에 있는 x가 되고
- 'male' if x 라는 문법에 의거해서 x의 값이 True이면 'male'이 되는것이고, 그것이 아니라면(else) 'female'로 되어서 age_df['gender']에 기록이 되는것이다.
3) 표준 정규분포 그리기

Q1. 실제 boneage의 평균과, 표준편차를 구하지 않고 표준정규분포(평균=0, 표준편차=1)를 사용하는 이유는?
A1. 각 집단마다 평균과 표준편차가 각각 다르다. 따라서 서로 분포를 비교하기가 어렵다는 문제가 생긴다. 그래서 평균=0, 표준편차=1인 표준정규분포를 그리게 되므로서, 다른 집단과 비교를 할 수 있다.
계산법은 다음과 같다.
우리가 수집한 개별데이터(boneage)에서 그 데이터 전체의 평균을 빼고, 표준편차로 나누면 된다.
이렇게 계산된 표준화된 개별 데이터를 'Z-Score'라고 부른다. Z-Score는 평균=0, 표준편차=1인 정규분포의 확률변수(확률밀도 함수의 x축)이 된다.
즉, 우리는 age_df['boneage']에서 평균과 표준편차를 구해서 적용시켜도 되지만, 그렇게 되면 다른 집단과 비교를 하기 힘드므로 표준정규분포를 따르는 것이다.
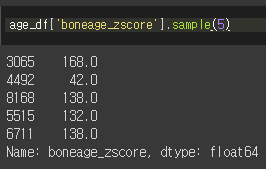
4) category 범위 지정

boneage를 일전한 비율을 10등분 해서 category화 시킨 것이다.
2. 연령 및 성별 분포 조사

3. Training Data와 Validation Data로 분류하기
데이터 전처리과정 중 필수적으로 중요한 내용중 하나가 바로 지금 부분이다. training dataset에서 우리는 train을 위한 dataset과 검증을 위한 validation dataset으로 나눈다.
*정확한 내용을 다음 포스팅을 참고 : https://sensibilityit.tistory.com/499
그래서 케라스에서는, model_selection내에 train_test_split 함수를 이용해서 분류할 수 있다.
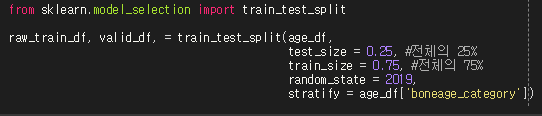
1) train_test_split() 함수
전체 데이터셋을 받아서 랜덤하게 tain/test dataset으로 분리해주는 함수이다.(여기서는 test대신 valid를 위한 것이다.)
[인자값 설명]
- test_size : 전체 데이터셋에서 test set의 비율을 의미. [기본값 : 0.25]
- train_size : 전체 데이터셋에서 train set의 비율을 의미.[기본값 : None]
==> test_size와 train_size의 합은 1.0이 되어야 한다.
- random_state : 정수 값을 입력하면 random하게 생성될때 사용되는 random seed를 사용.(어떠한 값을 줘도 상관은 없다.)
-stratify : train/test dataset들의 원래 input dataset의 클래스 비율과 같은 비율을 가지도록 지정을 해주는 것이다.
===> 따라서, 위에서도 boneage를 균일하게 10등분 해준 것이다.
아래와 같이 비율에 맞게 랜덤하게 분류된것을 볼 수 있다.

4. 훈련 데이터셋을 균형있게 분포를 수정.
2번째 글 중에서 '연령 및 성별 분포 조사'를 보면, 'boneage'와 'male'의 분포가 균일하게 되어있지 않을것을 볼 수 있다. 옳바른 훈련을 하기 위해서 training dataset의 분포를 균형있게 조정해 주어야 한다.

그래서 위와 같이 진행을 한다.
*참고 사이트
- apply()에 대한 내용 : https://datascienceschool.net/view-notebook/aa62265f02fc429aa636ef343c3b1fda/
- sample()과 같은 분포에 대한 내용 : https://rfriend.tistory.com/tag/sample%28%29
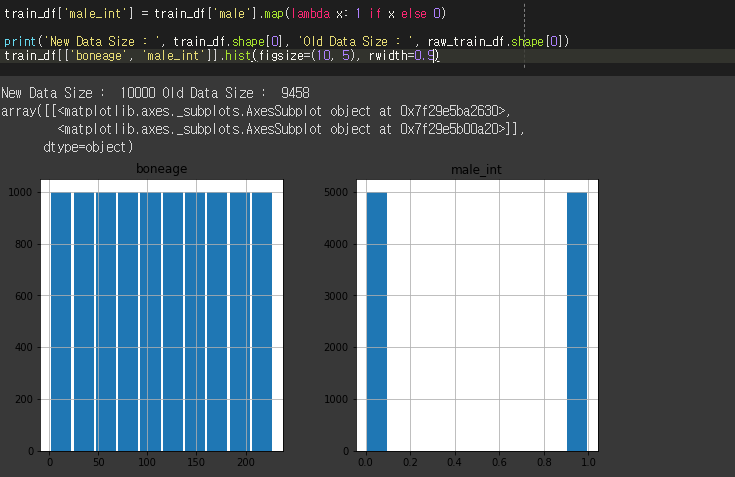
male은 True와 False의 값으로 되어있어서 현재 Numpy버전에서는 히스토그래프로 그리는것이 불가능하다. 이것을 True일때 1 False일때 0으로 변경해줘서 그래프를 그렸다.

이 raw_train_df그래프와 비교를 해보면 확실히 다른점을 볼 수 있다.
5. Image Generator로 데이터 Augumentation하기
1) ImageDataGenerator 클래스를 이용해서 객체 생성

이 클래스의 역할은, Image Data의 영상 개수가 매우 부족하니, 돌리고 이동하고 변형시켜서 Image Data를 Augumentation(증식)시키는 것이다.
* ImageDataGenerator 참고 문헌 : https://keras.io/preprocessing/image/#imagedatagenerator
2) ImageGenerator 생성

첫번째 줄에서, in_df(input dataframe)엥서의 경로에 해당되는 열(column)의 값이 base_dir로 저장된다는 것이다.
그리고, ImageDataGenerator 클래스를 이용해서 객체를 생성하고, flow_from_directory() 함수를 호출해서 Generator를 생성한다.
*참고 : https://tykimos.github.io/2017/03/08/CNN_Getting_Started/
여기까지가 ImageDataGenerator 클래스 생성해서 생성된 클래스를 이용해서 제너레이터를 생성하는 것이다.
3) 각 용도별 Generator 적용

이것들의 shape를 찍어보면 다음과 같다.
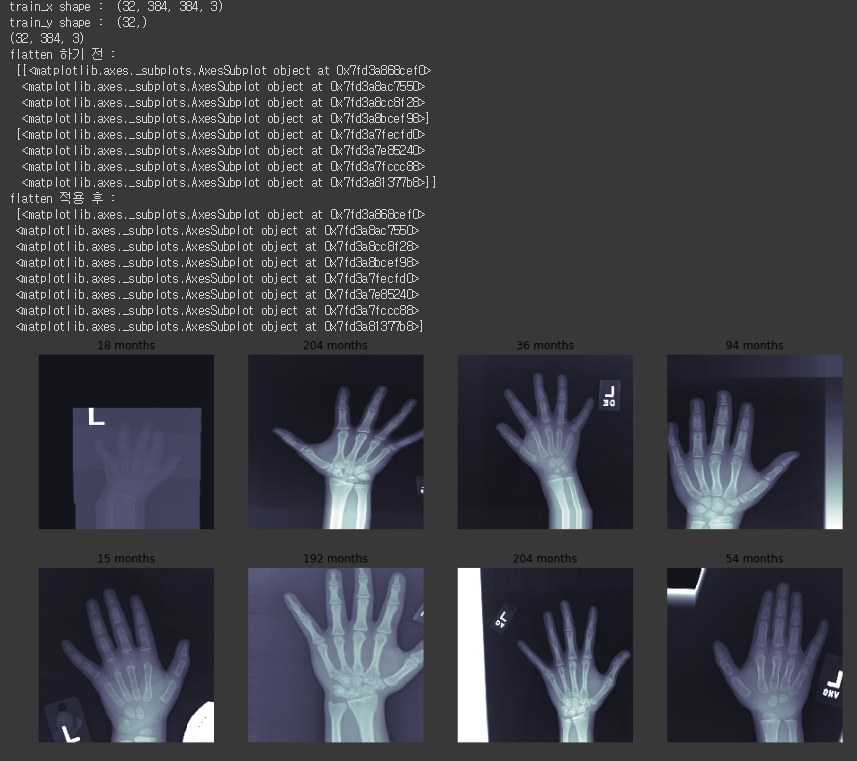
4) 훈련 전, 전처리 거친 이미지들 확인

for문에서 cmap='bone'을 해준것과 vim=-127, vmax=127을 해준 것은, x-ray 이미지 데이터를 확인할때 가장 이상적인 값인거로 생각이 든다.(확실하지 않아요~)
subplot명령은, Grid형태의 Axes객체들을 생성하는데 Figure 행렬이고, Axes가 그 행렬의 원소라고 생각하면 된다. 근데 여기서는 subplots 명령을 사용한다. 이 명령으로 복수의 Axes 객체를 동시에 생성할 수 있으며, 2차원의 ndarry 형태로 Axes 객체가 반환된다.
따라서, m_axs가 일단 '밑그림'이라고 생각을 하자, x-ray가 보여지기 위해서 일단 밑그림을 그리고, fig로 x-ray 데이터를 입힌거라고 생각을 하자.
*참고 : subplots에 대한 글 : https://datascienceschool.net/view-notebook/d0b1637803754bb083b5722c9f2209d0/
여기까지가, x-ray image data의 id, 뼈나이, 성별 등과 같은 정보를 가지고 있는 csv파일과 실제 이미지 데이터를 비교해서 빠진 부분이 없는지(결측값)을 확인하고 모델을 훈련하기 전 train dataset, validation data set, test dataset을 나누고 의료영상 데이터가 턱 없이 부족하니, ImageDataGenerator를 거쳐서 Data Augumentation(데이터 증식)을 하는 과정이다.
다음 포스팅은, 전처리를 한 데이터를 이용해서 실제 모델을 학습하고 test dataset이 들어오면 bone age가 몇인지 예측하는 것을 해보도록 하겠습니다.
'Python > 머신러닝&딥러닝' 카테고리의 다른 글
| [GAN] Generative Adversarial Network 정리 (0) | 2019.10.17 |
|---|---|
| (Tensorflow_eager)Mnist와 AlexNet을 이용한 CNN (0) | 2019.07.21 |
| 딥러닝 필수 기본 개념 (0) | 2019.05.19 |
| Ch02. 퍼셉트론(밑바닥부터 시작하는 딥러닝) (1) | 2019.04.12 |
| ch04. 신경망 학습(밑바닥부터 시작하는 딥러닝) (0) | 2019.03.30 |

