
 [생성모델 시리즈] Adversarial Latent Autoencoders
[생성모델 시리즈] Adversarial Latent Autoencoders
■ 본 논문은, GAN의 Generator → F, G & Discriminator → E, D 각각 분리하여 아키테처를 구성하고 있습니다. ■ F에서 나온 latent space와 E에서 나온 latent space가 서로 동일한 분포를 가진다고 가정해서 연구가 진행 되었으며, F는 deterministic하게 latent space mapping이 이루어지고, G﹒E는 독립적이고 이미 알려진 분포의 noise인 η를 입력으로 주어 stochastic하게 만듭니다. ■ 결론적으로 latent space의 확률 분포를 adversarial 하게 학습할 수 있는 장점이 있습니다. 그로 인하여 GAN과 비슷한 생성 능력, disentangled representation을 학습한 점을 보여주고 있습..
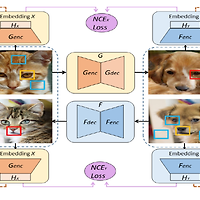 [DCLGAN] Dual Contrastive Learning for Unsupervised Image-to-Image Translation
[DCLGAN] Dual Contrastive Learning for Unsupervised Image-to-Image Translation
Abstract Unsupervised image-to-image translation개념 Unsupervised image-to-image translation tasks는 unpaired train data에서 source domain X와 target domain Y간의 mapping이 되는 지점을 찾는 것을 목표로 하는 task 입니다. CUT(Contrastive Learning for unpaired image-to-image Translation) Contrastive Learning for unpaired image-to-image Translation은 두개의 도메인 (X, Y) 모두에 대해 하나의 Encoder만 사용하여 입력, 출력 패치(patch)의 mutual information..
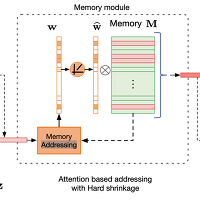 [MemAE]Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection -1
[MemAE]Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection -1
1. Abstract 정상 데이터를 이용하여 Autoencoder(AE)을 학습하면 정상보단 비정상 데이터에 대해 더 높은 재구성 오류(reconstruction error)을 얻게 됩니다. 하지만 AE는 일반화(Generalization)가 잘 이루어진다는 특징이 있어서 비정상 데이터가 입력되어도 정상을 재구성 해야하지만 결함이 있는 부분까지 포함하여 재구성 하는 경우가 발생하게 됩니다. 이런 AE기반 이상 탐지(Anomaly Detection)의 한계점을 개선하기 위한 해결책으로 메모리 모듈(memory module)을 사용하여 AE을 augmented 하는 방법인 MemAE을 이 논문에서는 제안하고 있습니다. 방법은 (1) 입력 x가 주어지면 MemAE는 먼저 Encoder을 통..
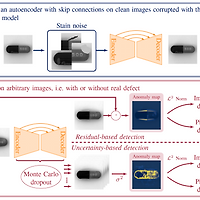 [Anomaly Detection] Improved anomaly detection by training an autoencoder with skip connections on images corrupted with Stain-shaped noise
[Anomaly Detection] Improved anomaly detection by training an autoencoder with skip connections on images corrupted with Stain-shaped noise
1. Abstract [산업 현장에서 AE를 활용한 Anomaly Detection] Industrial vision에서 Anomaly Detection problems은 결함이 있거나 없는 arbitrary image를 clean image에서 mapping하도록 훈련된 AutoEncoder를 사용하여 해결할 수 있습니다. [skip-connections이 있는 AutoEncoder(AES)를 사용한 이유] 이 접근 방식에서 Anomaly Detection과정은 개념적으로 본다면 reconstruction residual 또는 reconstruction uncertainty에 의존합니다. 공통적으로 sharpness of the reconstruction를 높이기 위해 skip-connections이 ..
 [Pix2Pix] Image-to-Image Translation with Conditional Adversarial Network
[Pix2Pix] Image-to-Image Translation with Conditional Adversarial Network
1. Abstract image-to-image translation problems에 대한 일반적인 방법부터 Contitional adversarial networks를 사용한 방법까지 조사했다. Image-to-Image translation problems를 다루는 Networks는 입력 이미지에서 출력 이미지로 가는 mapping을 학습할 뿐만 아니라 loss function도 학습한다. 이를 통해 image-to-image translaotion problems에서 각 상황에 따라 사용되는 loss functions이 달랐지만 paper에서 제안한 방식을 적용하면 동일한 loss functions을 사용하여 적용할 수 있다. paper에서 제안한 방법을 사용하면 label maps에서 사진을 합..
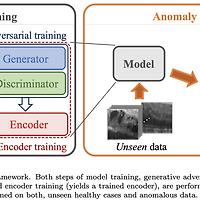 [F-AnoGAN] Fast Unsupervised Anomaly Detection with GAN
[F-AnoGAN] Fast Unsupervised Anomaly Detection with GAN
1. Abstract [문제점] 정확한 annotation은 시간이 많이 들기 때문에 전문가(방사선사, 의사 등)가 clinical imaging(임상 영상)을 직접 annotation을 표시한 데이터를 얻는 것은 어렵다. 또한 모든 병변에 대해 annotation이 표시되지 않을 수도 있으며 annotation에 대해서 정확하게 이 병변이 어떤 병변인지 설명 되어있지 않은 경우도 있다. [Supervised Learning의 장단점] 전문가로부터 분류된 training data를 받아 Supervised Learning 방식으로 모델을 학습 시키면 좋은 성능을 얻는 반면, annotation이 표시된 병변으로만 제한이 되는게 단점이다. [Unsupervised Learning으로 접근한 f-AnoGAN..
 [StyleGAN] A Style-Based Generator Architecture for Generative Adversarial networks
[StyleGAN] A Style-Based Generator Architecture for Generative Adversarial networks
1. Abstract We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature 라고 논문 초반 부분에 나와있다. 해당 논문에의 핵심은, Generator Architecture를 중심적으로 설명하고, 이 Architecture를 기존에 하던 방식(PGGAN)과는 다른 방법으로 구성을 했다라는게 핵심 포인트이다. 또한 Image에 Style을 scale-specific control하게 적용 했다 라고 주장을 하고 있다. 그럼 여기서 Style을 scale-specific control하게 적용한 의미가 무엇인지 한번 짚고 넘어가보자. Q..
 [AnoGAN] Unsupervised Anomaly Detection with GAN 정리
[AnoGAN] Unsupervised Anomaly Detection with GAN 정리
Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide MArker Discovery 일명 "AnoGAN"에 대한 paper을 읽고 정리한 공부자료 입니다. 기본개념 GAN이란? GAN의 학습 과정은, Discriminator가 Real과 Fake를 잘 맞추도록 훈련을 한 다음, Generator가 만들어낸 Fake image가 Discriminator에서 Real로 나오도록 하는 학습 과정입니다. DCGAN - CNN vs MLP MLP : 3차원 데이터를 1개의 Vector로 풀어서 인식한다. 그로인해 단점은 이미지의 위치 정보를 무시하게 된다(feature loss발생) CNN : 3차원 데이터 입력을 그대로 사용한다..