
티스토리 뷰
[Pix2Pix] Image-to-Image Translation with Conditional Adversarial Network
Waterbottle 2020. 8. 2. 21:381. Abstract
image-to-image translation problems에 대한 일반적인 방법부터 Contitional adversarial networks를 사용한 방법까지 조사했다.
Image-to-Image translation problems를 다루는 Networks는 입력 이미지에서 출력 이미지로 가는 mapping을 학습할 뿐만 아니라 loss function도 학습한다. 이를 통해 image-to-image translaotion problems에서 각 상황에 따라 사용되는 loss functions이 달랐지만 paper에서 제안한 방식을 적용하면 동일한 loss functions을 사용하여 적용할 수 있다.
paper에서 제안한 방법을 사용하면 label maps에서 사진을 합성하고 edge maps에서 object를 reconstruction하고, 흑백 사진을 컬러 사진으로 채색하는데 효과적이다.
실제로 이 paper와 관련된 pix2pix software가 출시된 이후로 많은 아티스트 및 사용자들이 pix2pix software를 이용하여 매개변수를 조정할 필요 없이 광범위한 사용 가능성을 보여준다.
pix2pix는 입력 이미지에서 출력 이미지로 가는 mapping functions을 수작업으로 설계 하지 않고도 합리적인 결과를 얻을 수 있다는 것을 보여준다.
2. Pix2Pix (Supervised Learning)
Pix2Pix 는 크게 볼 때 Supervised Learning입니다. 그치만 사용되는 dataset에 따라서 self-supervised Learning이 될 수도 있습니다. 예시로는 컬러 사진을 흑백사진으로, 또는 흑백 사진을 컬러 사진으로 변경해주는 모델을 만들때 self-supervised Learning으로 구분을 지을 수 있습니다.
2-1. 컬러 사진 → 흑백 사진
Methods: Self-Supervised Learning
👉 사람이 label을 붙여줄필요 없이 color 사진을 인터넷 어딘가에서 다운 받으면 영상처리 기법(ex, cv2 등)을 이용해서 흑백 사진으로 변경 해주면 되니까 엄밀히 따지자면 Self-Supervised Learning이라고 부를 수 있습니다.
Loss: Minimize the difference between output 'G(x)' and ground truth 'y'

2-2 . 건물 픽셀 그림 → 실제 건물 외벽 사진
Methods: Supervised Learning
👉 이미지와 건물 외벽 Label이 존재하니 Supervised Learning
Loss: Minimize the difference between output 'G(x)' and ground truth 'y'

2-3. Pix2Pix 모델이 나오기 전
⭐️ 단순 Pixel-Level에서 'L1(G(x) - y)'를 최소화 하면 어떻게 될까?
🗣 Pixel-Level difference만 Loss로 취하면 (그림 3) 처럼 이미지가 Blur해지며 회색조를 띄는 이미지를 얻게 된다.

따라서 해당 저자는 사람이 봐도 진짜와 가짜가 확연히 구별이 가능한데 사람이 할 수 있다면 딥러닝 모델도 할 수 있어야 하는거가 아닌가? 라는 아이디어로 단순 Pixel Level에서 이미지의 차이만을 Loss로 가졌다면, GAN Loss를 추가해서 사용한게 바로 Pix2Pix 모델입니다. (자세한 내용을 아래에서 추가로 정리를 해보도록 하겠습니다.)

3. Model Architecture

3-1. Generator
Encoder-Decoder
Encoder-Decoder는 입력된 이미지에서 핵심 Feature들만 뽑는 구조이며 Bottleneck을 갖고 있습니다. "Bottleneck 구조를 갖는 모델은 Image-to-Image translation tasks에서 많이 사용되는 구조이며 결과 이미지의 형태들이 급진적으로 변화하는 특징"을 갖고 있습니다.
Pix2Pix의 목표는 입력된 이미지를 우리가 원하는 이미지로 변형 시켜주는 것 입니다. paper figure들을 보면 알겠지만 이미지 형태는 그대로 유지된 채 색체, 내부 구조 들만 변경되는 것을 볼 수 있습니다. 따라서 Encoder-Decoder를 이용하면 성능이 제대로 안나올 뿐더러 해당 tasks에 어울리지 않는 구조입니다.. 그래서 "Pix2Pix에서는 Skip-connection을 사용한 U-Net 구조를 사용"했습니다.
🤜 Encoder-Decoder 구조의 장단점
- 장점 : bottleneck 구조를 갖고 있어서 핵심 Feature를 추출해낼 수 있으며 domain이 다른 이미지로 변형을 하고 싶을때 적합하다.
- 단점 : 생성된 이미지의 Detail들이 떨어진다.
U-Net
U-Net 구조의 특징은 "Skip-connection이 있다보니 입력된 영상에 대한 detail들이 마지막 layer까지 잘 전달 된다는 특징"이 있습니다. 그래서 아무래도 Encoder-Decoder의 결과와 비교해보면 output image quality가 좋습니다. 그렇지만 단점도 존재합니다. "skip-connection은 depth가 거의 없다보니 depth가 어느정도 있는 다른 네트워크 구조에 비해 생성된 결과가 별로"라는 점 입니다..
🤜 U-Net 구조의 특징과 장단점
- 특징 : paired된 dataset이 어느정도 비슷한 컨텐츠들이 있는 경우 skip-connection을 많이 사용하는 경향을 보이고 있다.
- 장점 : 처음 detail들이 마지막 layer까지 잘 전달 된다.
- 단점 : skip-connection을 사용해서 depth가 거의 없다.
3-2. Discriminator
👉 PatchGAN을 사용 (참고 blog Link)

DCGAN의 Discriminator
이미지 전체를 보고 진짜인지 가짜인지 판별 합니다.
PatchGAN의 Discriminator
이미지 전체에서 Receptive field 크기 만큼 특정 Patch(receptive field) 부분을 보고 그 부분이 진짜인지 가짜인지 판별 합니다..
4. Loss
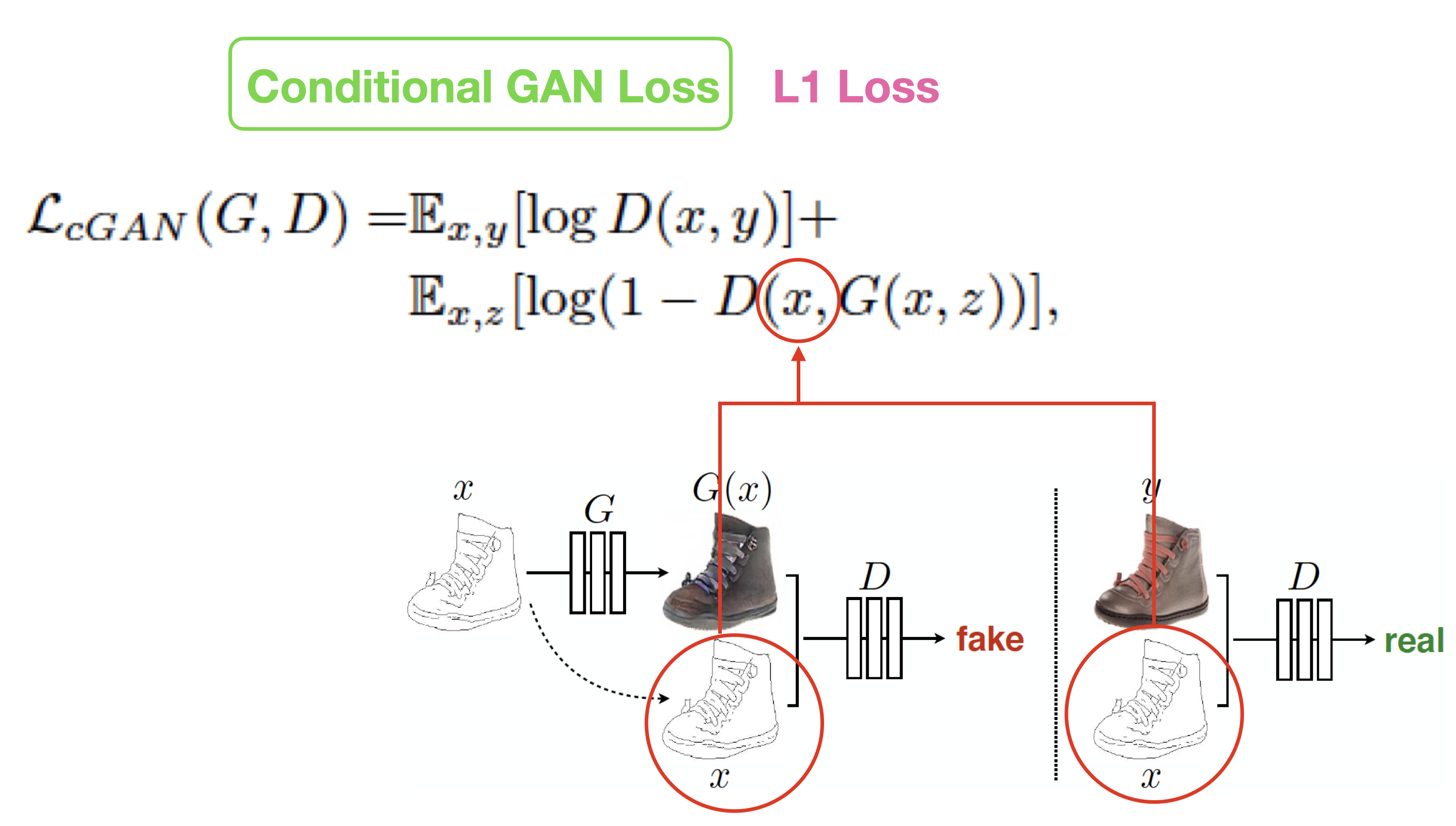
4-1. Conditional GAN Loss (CGAN Loss)
특이한점은 Discriminator의 입력 이미지에 생성된 G(x) 이미지와 training data인 x를 넣어줍니다. 이는 Conditional 효과를 줘서 GAN이 학습을 할 때 방향성을 잡아주는 역할을 합니다.
4-2. L1 Loss
L1 loss는 (그림 8)과 같이 original 이미지에서 generation 이미지의 Pixel-level에서의 차이를 구한 값입니다. L1 Loss는 학습을 진행할 때 Euclidean distance를 최소화 하는 방향에 집중을 하는 성향이 있습니다.
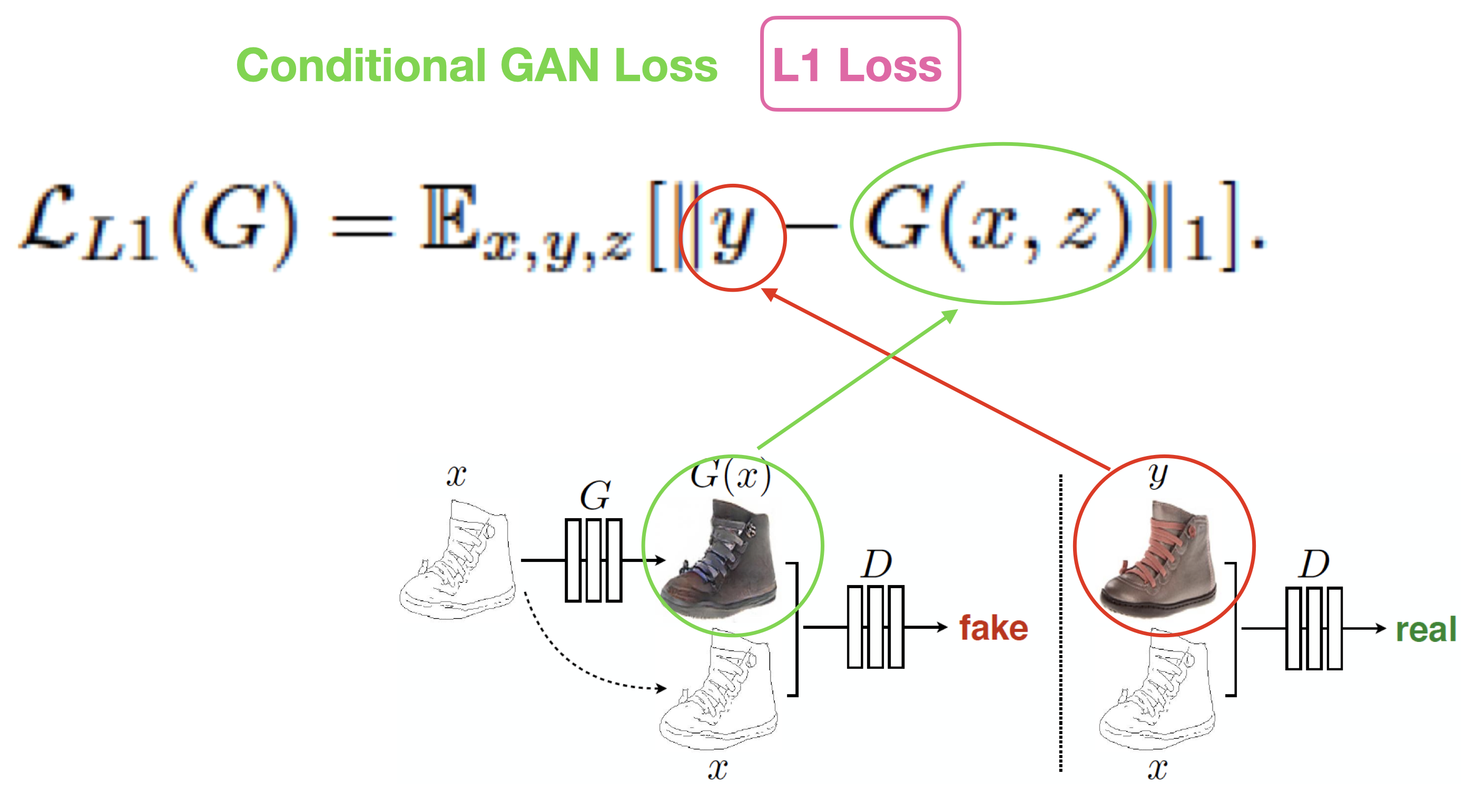
그래서 최종적으로 (그림 4)와 같이 L1 loss와 Conditional GAN Loss (CGAN Loss)를 함께 사용해야지 퀄리티 좋은 이미지를 얻을 수 있게 됩니다.
Reference
✔️ Pix2Pix paper [Link]
✔️ PatchGAN Discriminator 뽀개기 [Link]
✔️ Receptive Field Wikipedia [Link]



