
티스토리 뷰
■ 본 논문은, GAN의 Generator → F, G & Discriminator → E, D 각각 분리하여 아키테처를 구성하고 있습니다.
■ F에서 나온 latent space와 E에서 나온 latent space가 서로 동일한 분포를 가진다고 가정해서 연구가 진행 되었으며, F는 deterministic하게 latent space mapping이 이루어지고, G﹒E는 독립적이고 이미 알려진 분포의 noise인 $\eta$를 입력으로 주어 stochastic하게 만듭니다.
■ 결론적으로 latent space의 확률 분포를 adversarial 하게 학습할 수 있는 장점이 있습니다. 그로 인하여 GAN과 비슷한 생성 능력, disentangled representation을 학습한 점을 보여주고 있습니다.
🗣 ALAE(Adversarial Latent Autoencoders)에 대한 리뷰 후 다음 글에서 코드 리뷰를 이어 나가도록 하겠습니다.
✔️ [논문 리뷰] Adversarial Latent Autoencoders
◻︎ [코드 리뷰] Adversarial Latent Autoencoders
1. Abstract
Autoencoder란?
autoencoder는 encoder-generator map을 동시에 학습하여 generation & representation properties을 결합하는 것을 목표로 하는 unsupervised 접근 방식 입니다.
Autoencoder의 한계
Autoencoder에 대한 많은 연구가 진행되었지만, GANs(Generative Adversarial Networks)와 동일한 생성 능력을 가지고 있는지, 아니면 disentangled representations을 학습하는지에 대한 문제는 완전히 다루어지지 않았습니다.
제안
본 논문에서는 위에서 언급한 문제인
- GANs와 동일한 생성 능력을 가지고 있는지
- disentangled representations을 학습하고 있는지
에 대한 문제를 해결하는 autoencoder를 소개하며 저자들은 이 네트워크를 ALAE(Adversarial Latent Autoencoder)라고 부릅니다.
2개의 Autoencoder 설계
본 논문에서는 2개의 autoencoder를 설계했습니다.
- MLP Encoder를 기반으로 하는 Encoder
- StyleGAN의 Generator를 기반으로 하는 StyleALAE
StyleALAE는 StyleGAN과 비슷한 품질읜 1024x1024 얼굴 이미지를 생성할 수 있으며, 동일한 해상도에서 실제 이미지를 기반으로 face reconstruction, manipulations도 생성할 수 있음을 보여주고 있습니다.
결론적으로, ALAE는 GAN의 성능과 비슷하거나 그 성능을 능가하는 최초의 Autoencoder라고 논문에서 소개를 하고 있습니다.
2. Introduction
지금까지 발표된 이미지 생성 네트워크를 보면 아래와 같이 크게 두가지 특징을 관심있게 볼 수 있습니다.
- GAN처럼 얼마나 고해상도 이미지를 실제와 똑같게 생성할 수 있는지
- disentangled representations 학습이 잘 이루어졌는지
지금까지 진행된 연구들의 논문들을 보면, 고해상도 이미지를 생성하는 네트워크가 무엇이 있을까 생각을 해볼 때 AE(Autoencoder)보다는 GAN이 가장 먼저 떠오를 것 입니다. 또한 AE는 entangled representations을 배원 manipulations가 불가능 했습니다.
이 논문의 저자들은, abstract에 정리한대로 2가지의 autoencoder를 제안하고 있습니다. 첫째, MLP Encoder를 기반으로 하는 Encoder인 ALAE, 둘째, StyleGAN의 Generator를 ALAE에 적용한 StyleALAE.
StyleALAE의 생성 결과부터 보면 아래 그림 1와 같이 GAN처럼 고해상도 이미지를 잘 생성하고 있음을 보여주고 있습니다.

3. Preliminaries
3-1. AutoEncoder

Encoder
입력된 이미지에 대한 특징(feature)인 고차원 input space을 저차원 latent space $z$로 압축하는 모델이며 식을 다음과 같습니다.
$$z = E(x)$$
Decoder
Encoder에 의해 고차원에서 저차원으로 인코딩된 $z$를 다시 입력된 이미지 $x$와 동일한 이미지 $\hat{x}$로 재구성 하는 모델이며 식은 다음과 같습니다.
$$\hat{x} = D(z)$$
3-2. GANs

Generator와 Discriminator로 구성되어 있으며 서로 adversarial training 하는 방식으로 고해상도 이미지를 생성하도록 학습하는 생성 모델 입니다. 이는 $q(x)$가 $P_D(x)$만큼 가깝도록 G를 학습하는 것을 목표로 하게 됩니다.
Generator
Autoencoder처럼 입력 이미지 $x$를 latent space로 직접 인코딩하는 방식이 아니라, synthetic distribution $q(x)$를 표현하는 새로운 이미지 $G(x)$를 생성하기 위해 이전에 알려진 $p(z)$의 latent space $Z$를 학습하는 네트워크 입니다.
Discriminator
학습 데이터셋의 true distribution $P_D(x)$를 나타내는 이미지와 생성된 이미지의 false distribution $P_D(\hat{x})$을 나타내는 이미지를 구분하는 네트워크 입니다.
참고: [GAN] Generative Adversarial Network 정리
3-3. Adversarial Latent Autoencoders
Autoencoder는 지금가지 많은 연구가 진행되었습니다. 하지만 아래 2가지 문제에 대해서는 해결을 하지 못하고 있습니다.
- GANs와 비슷한 생성 능력을 가지고 있는지.
- Disentangled representations을 잘 학습하였는지.
일반적인 autoencoder만으로는 disentangled representation을 학습하기 힘들고 이를 학습하기 위해서는 추가적인 테크닉이 필요.
일반적인 GAN은 entangled representation을 학습합니다. 따라서 input noise에서 어느 부분이 어떤 representation을 조절하는지 알기 힘듭니다. 근데 이것을 모델이 disentangle하게 학습한다면 input noise의 어느 부분이 어떤 representation을 조절하는지 해석이 가능하게 됩니다. GAN에서는 disentangled representation을 학습하는 모델들이 많이 나왔지만 Autoencoder는 그렇지 않았습니다.
그래서 이 논문은 위에서 언급한 두기자 문제를 모두 해결하는 Autoencoder를 설계를 했습니다.
4. Architecture
ALAE의 구조에 대해 알아보고 StyleGAN의 Generator을 이용하여 GAN과 비슷한 생성 능력을 지닐 수 있도록 만든 StyleALAE에 대해 알아보도록 하겠습니다.
4-1. ALAE

ALAE는 generator G, discriminator D를 $\textit{G} = F \circ G $ and $\textit{D} = D \circ E $로 decomposing한 네트워크 입니다. 이때 decomposed 네트워크 사이의 latent space $w$즉, $w = F(z)$와 $w = E(q_G(x\vert w, \eta))$가 서로 동일하다는 가정을 지니고 있으며 이 latent space를 $W라고 표현하고 있습니다.
◼︎ Generator F
F는 prior distribution $p(z)$ → intermediate latent space $w$ distribution $q_F(w)$로 변환하는 역할을 가지고 있습니다.

이 논문에서 disentanglement에 대해 아주 중요한 이야기를 하고 있습니다.
input space에서 멀리 떨어진 intermediate latent space가 더 나은 disentanglement properties를 갖는 경향이 있음을 보여주고 있습니다.
따라서 저자는 F가 가장 일반적인 경우에서 deterministic map 이라고 가정했으며 know prior $p(z)$에서 샘플을 가져와 $q_{F}(w)$을 출력하게 됩니다.
deterministic mapping에 대해 궁금하신 분들인 해당 wiki를 참고해 참고해주시기 바랍니다.
◼︎ Generator G
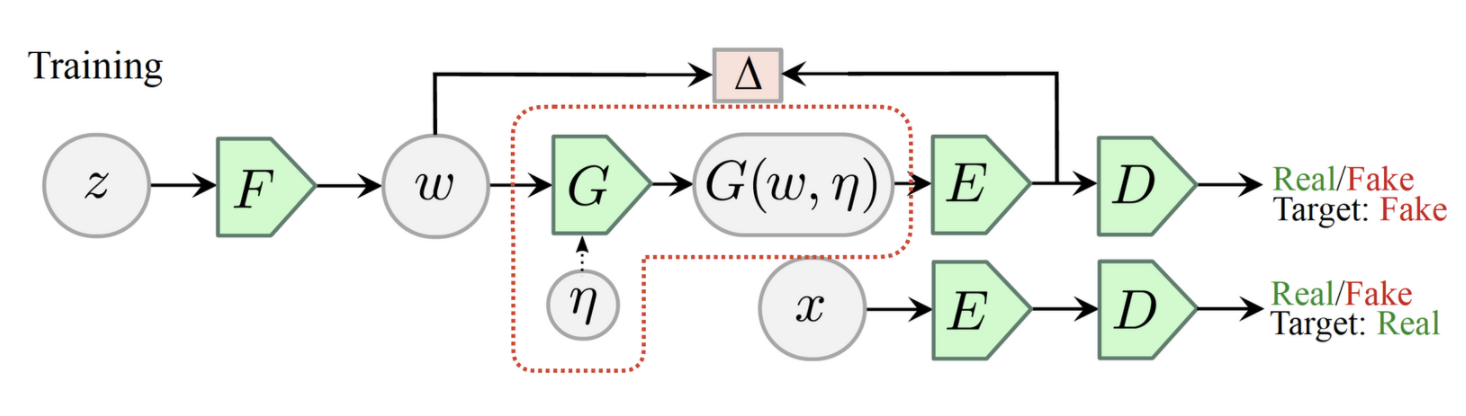
original GAN과 차이점 부터 비교해가며 알아보겠습니다.
GAN
- Generator, Discriminator 2개의 네트워크로 adversarial training이 이루어집니다.
- Generator에 대한 입력은 latent space에서 직접 샘플링이 됩니다.
- 생성된 이미지 $G(z)$는 binary classifier처럼 True/False로 분류해주는 Discriminator에 바료 입력 됩니다.
ALAE
- Generator, Discriminator가 $\textit{G} = F \circ G $ and $\textit{D} = D \circ E$로 decompose 되었으며 총 4개의 네트워크로 adversarial training이 이루어집니다.
- F에서 학습된 intermediate latent space $w$에서 샘플링이 됩니다.
- G에서 생성된 이미지가 Encoder를 먼저 거친 위 Discriminator에 입력 됩니다.
저자는 G가 known fixed distribution $p_\eta(\eta)$에서 샘플링된 independent noisy input $\eta$에서 optionally하게 의존할 수 있다고 가정하고 있습니다. 따라서 G는 $q_F(w)$와 optionally $p_\eta(\eta)$2가지 입력을 동시에 받습니다. 해당 식은 다음과 같이 정의됩니다.

$q_G(x\vert w, \eta)$: $w$ and $\eta$가 주어지면 생성된 이미지 $\hat{x}$의 조건부 확률
◼︎ Discriminator Encoder E

위에서 언급한대로 decomposed 네트워크 사이의 latent space가 서로 동일하다는 가정을 지니고 있습니다. 즉, intermediate latent space $w$로 data space를 인코딩하며 이는 $q_F(w)$와 동일한 latent space를 갖습니다.
학습중에 Encoder에 대한 입력은 real data distribution $P_D(x)$의 real image $x$ 또는 synthetic distribution $q(x)$를 나타내는 생성 이미지 $\hat{x}$인 $G(w, \eta)$ 입니다.
synthetic distribution에서 입력될 때 Encoder의 출력은 다음 식과 같습니다.

$q_E(w)$: 주어진 data space에서 latent space $w$의 conditional probability distribution
실제 real data distribution $P_D(x)$에서 입력될 때 Encoder의 출력은 아래 식과 같습니다.
$$ q_{E, D}(w) = \int_{x} q(w \vert x) P_D(x) dx$$
위와 같은 식이 성립되는 이유는 F에서 나온 intermediate latent space $w$와 E에서 나온 intermediate latent space $w$가 동일하다는 가정으로 연구가 진행되어서 $q_F(w) = q_E(w)$가 성립됩니다.
ALAE는 adversarial strategy로 학습이 진행됩니다. 따라서 $q(x)$ → $P_D(x)$가 되며 이는 $q_E(x)$ → $q_{E, D}(x)$로 이동하는 것을 의미합니다.
◻︎ Matching the latent space
latent space에 대한 가정은 $q_E(w)$의 output distribution이 $q_F(w)$의 input distribution과 유사하다는 점 입니다. 이 개념을 바탕으로 실제 학습을 진행할 때 두 분포간 squared difference를 최소화 하는 방향으로 학습을 진행합니다.
◻︎ AE가 GAN처럼 선명한 이미지를 만들 수 없는 이유!
일반적인 autoencoder에서 입력된 이미지와 Decoder에 의해 복원된 이미지를 이용하여 reconstruction loss를 구하게 됩니다. 이때 사용된 loss functiondms 보통 L2 loss를 많이 사용합니다. autoencoder가 GAN처럼 선명한 이미지를 생성(복원)할 수 없는 가장 큰 이유가 바로 L2 loss를 사용하기 때문인데요. L2 loss는 data space에서 연산이 이루어지지만 human visual perception을 반영하지는 않습니다. 이러한 이유로 인해 autoencoder가 GAN과 같은 선명한 이미지를 생성할 수 없게 됩니다.
◼︎ Discriminator D
Encoder에 의해 제공되는 intermediate latent space가 입력되면 진짜인지 가짜인지 판별해주는 역할을 하는 네트워크 입니다. 이 네트워크는 학습 과정에서 2번 호출 됩니다.
- G에 의해 생성된 이미지 $q_G(x\vert w, \eta)$가 E를 통해 latent space mapping이 이루어지고, 그 latent space $q_E(w)$가 D에 제공되는 경우.
- 실제 데이터 $x$가 E에 입력되고 그로 인해 얻어진 출력값이 D에 제공되는 경우.
4-2. StyleALAE
위 내용까지는 MLP Encoder를 기반으로 하는 ALAE에 대한 특징 및 아키텍처에 대해 알아보았습니다. 이제 StyleGAN의 Generator을 이용하여 GAN과 비슷한 생성 능력을 지닐 수 있도록 만든 StyleALAE 아키텍처에 대해 간단히 알아보겠습니다.

StyleALAE는 StyleGAN의 Generator와 ALAE를 결합한 아키텍처 입니다. StyleALAE는 아래와 같이 구성됩니다.
- (그림 9)와 같이 ALAE의 Generator가 StyleGAN의 Generator로 변경
- style information을 추출하는 Encoder network E는 Generator와 대칭이 되도록 구성.

◼︎ 개념 정리
◻︎ IN(Instance Normalization)
각 레이어 $i^{th}$의 style content를 추출하며, 입력된 영상에 대한 normalization을 진행합니다.
◻︎ Style Information
IN에 의해 추출된 style content를 구성하는 channel-wise average $\mu$와 $\sigma$를 의미합니다.
Encoder는 $i^{th}$의 style content들은 latent space $w$와 선형적으로 관련된 symmetric generator (G of StyleALAE)의 AdaIN(Adaptive Instance Normalization)으로 입력됩니다. 따라서 Encoder의 각 레이어의 IN에 의해추출된 style content는 multilinear map을 통해 latent space에 mapping 됩니다.
AdaIN에 대한 설명 [link]



