
티스토리 뷰
[Anomaly Detection] Improved anomaly detection by training an autoencoder with skip connections on images corrupted with Stain-shaped noise
Waterbottle 2020. 9. 21. 18:201. Abstract
[산업 현장에서 AE를 활용한 Anomaly Detection]
Industrial vision에서 Anomaly Detection problems은 결함이 있거나 없는 arbitrary image를 clean image에서 mapping하도록 훈련된 AutoEncoder를 사용하여 해결할 수 있습니다.
[skip-connections이 있는 AutoEncoder(AES)를 사용한 이유]
이 접근 방식에서 Anomaly Detection과정은 개념적으로 본다면 reconstruction residual 또는 reconstruction uncertainty에 의존합니다. 공통적으로 sharpness of the reconstruction를 높이기 위해 skip-connections이 있는 AutoEncoder를 고려하게 되었습니다.
[AES + Stain noise model 제안]
Reconstruction 과정 중 clean image가 나오게끔 하기 위해서 train image의 Clean image만 학습으로 진행하는 전략은, reconstruction을 담당하는 Network가 입력하는 대로 출력을 해버리는 identity mapping으로 수렴 되는것을 방지하기 위해 Noise model로 train image를 손상시키고 출력으로 Clean image가 나오도록 하는 목적으로 Stain noise model을 추가 할 것을 제안합니다.
[우리가 사용한 모델 짱짱👍 → AES+Stain model]
이 모델을 실제 결함 모양에 관계없이 임의의 실제 이미지에서 깨끗한 이미지를 재구성 하는 데 유리하다는 것을 보여줍니다.
[우리가 가라로 안했다는것을 증명하기 위해 이런 데이터셋으로 진행했다]
우리의 접근 방식의 관련성을 입증하는 것 외에도 우리의 검증은 pixel-wise및 image-wise anomaly detection을 위해 MVTec AD dataset에 대한 성능을 비교하여 reconstruction-based 방법에 대한 일관된 평가를 제공합니다.
2. Methods
[Anomaly Detection의 개요]
Anomaly detection은 Clean(Normal) data의 Distribution에 속하지 않는 다른 데이터들을 식별하는 작업으로 정의할 수 있습니다.
[Supervised Learning으로 하는 Anomaly Detection의 문제점]
Clean(Normal) data에 비해 Defective(Abnormal) data를 수집하는 것은 한계가 있고 만들다 하더라도 Data Imbalance가 발생합니다.

본 논문은 Unsupervised Learning으로 Anomaly Detection을 해결하는 논문입니다. 다만 이전에 정리했었던 AnoGAN, F-AnoGAN와의 차이점은 Query image가 입력으로 들어오면 그것을 구조는 동일하지만 Normal image로 image generation해주는 방법으로 GAN을 사용했습니다. 그러나 이 논문은 GAN이 mode collapse의 문제점을 지적하고 image generation 해주는 대신 image reconstruction 해주는 AutoEncoder 구조를 사용했습니다.
🤔 제 생각이지만 해당 저자는 F- AnoGAN과 AnoGAN의 방법만 인용했지, GAN 모델을 수정한 노력은 없어 보였습니다. 그래서 High resolution을 잘 생성해주는 GAN 모델들을 이용하면 mode collapse 문제는 많이 없어질텐데...좀 아쉽네요
3. Training Step
[Blue box]
아무튼 그림(1)의 모델의 구조를 뜯어보고 해석 해보도록 하겠습니다. 일단 Blue box를 보시면 GAN 같은 경우 Normal image를 generation 해주는 용도로 사용이 되지만, 여기서는 Skip-connections를 사용한 AutoEncoder(AES) 모델을 사용해서 입력 이미지로 query image가 들어오면 그것을 어떤 이미지가 들어오든 Normal image로 reconstruction 해주는 방법입니다.
Stain Model을 사용한 이유는 AutoEncoder는 입력 이미지가 들어오면 그것을 그대로 복원해주는 성질이 있습니다. 근데 Denoising AutoEncoder를 생각해보면 noise가 있는 입력 이미지가 들어오면 그것을 선명한 이미지로 reconstruction해주는 성질이 있어서 일반 AutoEncoder를 사용할때 보다 더 선명하게 reconstruction 해주는 경향이 있습니다.
마찬가지로 해당 논문에서는 얼룩 무늬를 추가해주는 Stain noise model을 이용해서 입력 이미지를 결함이 있는 이미지로 만들어줘서 다시 깨끗한 이미지로 복원될 수 있도록 하는 역할을 가지고 있습니다. 즉, Identity mapping이 안되도록 방지해주기 위해 Stain noise model을 사용하는 것 입니다.
좀 더 자세히 모델을 뜯어보도록 하겠습니다.

이 논문에서 사용한 데이터 크기는 256x256인 오직 Clean(Normal) Image로 학습되었습니다. 여기서 bottleneck 구조를 갖는 Skip-connection 을 사용함으로 써 model에 projection한 임의의 이미지로부터 좀 더 선명한 이미지가 reconstruction 된다고 합니다.
AESc 모델 구조를 보면 U-Net과 모양이 비슷하다는 생각이 자연스럽게 들게 됩니다. 그래서 한번 U-Net과 AESc를 비교 해보았습니다.
3-1. AESc vs U-Net
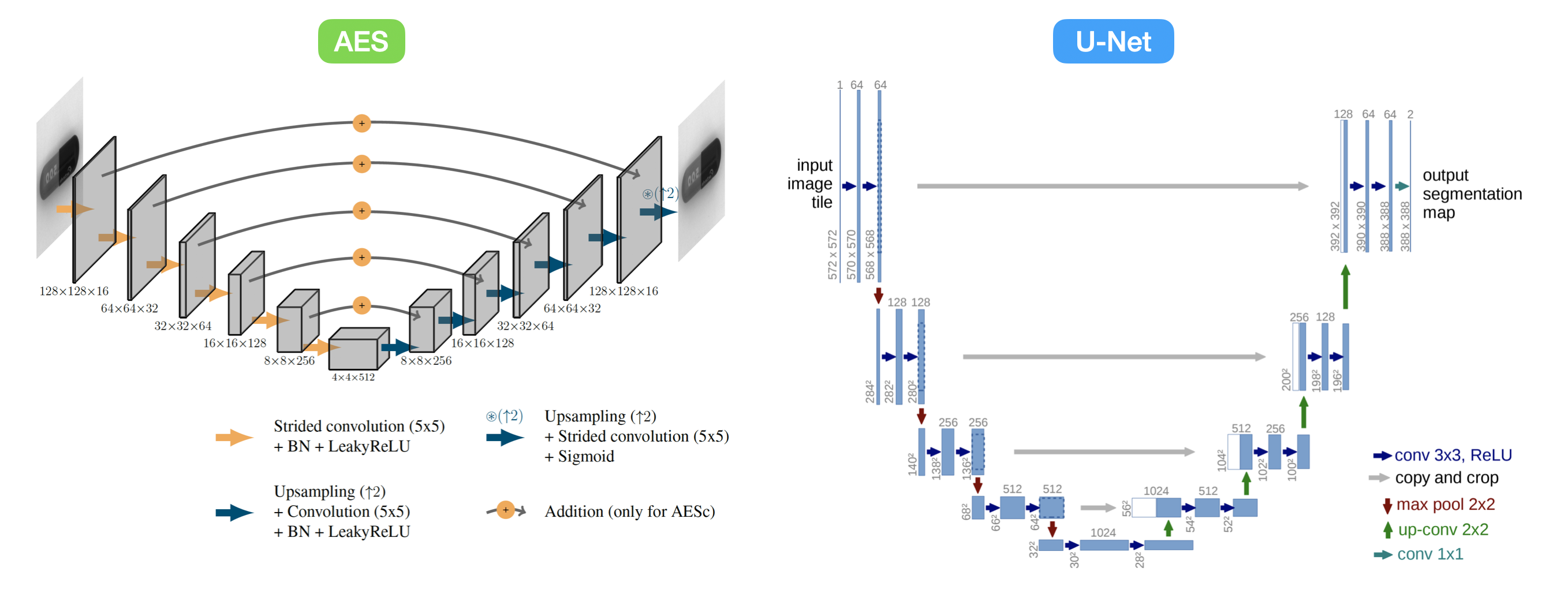
이 개념은 Pix2Pix 논문 리뷰 글에서 언급을 했었던 내용입니다. 다시 한번 정리를 해보겠습니다.
AutoEncoder
AutoEncoder는 입력 이미지에서 핵심 Feature들만 뽑는 구조이며 Bottleneck을 갖고 있습니다. Bottleneck 구조를 갖는 모델은 Image-to-Image translation tasks에서 많이 사용되는 구조이며 결과 이미지의 형태들이 급진적으로 변화하는 특징을 갖고있습니다.
🤜 Bottleneck 구조를 갖는 AutoEncoder 구조의 장단점
- 장점: Bottleneck 구조는 갖고 있어서 핵심 Feature를 추출해낼 수 있으며 Domain이 다른 이미지로 변형을 하고 싶을 때 적합하다.
- 단점: 생성(복원)된 이미지의 Detail이 떨어진다.
🤜 Bottleneck 구조를 갖는 AutoEncoder를 사용한 이유
추가적으로 Bottleneck 구조를 갖는 AutoEncoder를 사용한 이유는 Anomaly Detection tasks에서 defective structures를 image distribution에서 제외하는 것은 반복적으로 발생하는 문제라고 합니다. 그래서 Bottleneck 구조를 갖는 AE로 Feature map을 압축하는 과정은 Normal Image를 Manifold에 놓여지도록 reconstruction을 일반화 합니다.
U-Net
U-Net 구조의 특징은 "Skip-connection이 잇다보니 입력된 영상에 대한 detail들이 마지막 layer 까지 잘 전달 된다는 특징"이 있습니다. 그래서 아무래도 AutoEncoder의 결과와 비교해보면 output image quality가 더 좋습니다. 그렇지만 단점도 존재합니다. "Skip-connection은 depth가 거의 없다보니 depth가 어느정도 있는 다른 네트워크 구조에 비해 생성된 결과가 별로"라는 점 입니다.
🤜 U-Net 구조의 특징과 장단점
- 특징: paired된 dataset이 어느정도 비슷한 컨텐츠들이 있는 경우 skip-connection을 많이 사용하는 경향을 보이고 있다.
- 장점: 처음 detail들이 마지막 layer까지 잘 전달 된다.
- 단점: skip-connection을 사용해서 depth가 거의 없다.
Bottleneck 구조를 갖는 AutoEncoder에 Skip-connection을 사용한 이유
(그림 2)와 같이 Skip-connections을 사용하면 처음 detail들이 마지막 layer까지 전달되다 보니 reconstruction image가 보다 더 선명해 진다고 합니다. 근데! U-Net에서 Skip-connection을 사용할때는 Decoder 구조에 feature map을 Concatenation해서 사용했지만 해당 논문에선 encoder에서 decoder로 feature map을 Addition 시켜주었다고 합니다.
red box에서 다시 설명을 하겠지만, Skip-connection이 없는 그냥 AE를 사용해서 얻은 reconstruction image를 query image랑 MSE로 loss를 구하면 reconstruction image가 나중에는 결국 blurry한 image로 reconstruction됩니다. 또한 reconstruction loss가 커지게 되어서 엽력 이미지랑 모양이 똑같은 이미지로 복원이 잘 안이루어지게 됩니다.
GAN 말고 AESc를 사용한 이유
위에서도 언급한 내용으로 본 논문에서는 Clean(Normal) image를 복원 시키는 과정에서 GAN의 mode collapse 문제점을 지적하며 GAN 말고 Skip-connection을 사용한 AutoEncoder(AECs) 구조를 사용했습니다.
Anomaly Detection은 Unsupervised Learning으로 접근하고 있으며 그중에 대표적인 방법 중 GAN을 사용 안하는 이유는 딱 3가지 입니다.
- mode collapse로 인해 학습 하기가 어렵다.
- generative distribution에서 결합 샘플을 제외 못함 -> 이 문제는 AE에서 Bottleneck 구조로 해결.
- inference 과정시 query image의 distribution과 latent space에 속하는 가장 유하산 출력 이미지를 생성해야 하는 latent space 속의 latent vector를 찾기 위해서 추가적인 최적화 단계가 필요.
비교를 위해 AnoGAN과 여기서 제안한 방법을 비교해보았는데 당연히(?) 이 논문에서 제안한 방법이 더 잘 나왔다 라는 결과가 나와서 GAN 사용 안하고 AES + Stain Model을 사용한 것 같습니다.
🤔 개인적으로 여기서 의문이 드는 점은 AnoGAN의 GAN Architecture는 DCGAN으로 이루어져 있습니다. DCGAN은 mode collapse를 방지할 수 없어서 개선된 모델들이 더 많이 나왔습니다. 근데 굳이 64x64 이미지로 학습을 진행한 AnoGAN과 비교를 하다니.... 의문점이 많다는 생각이 들었습니다.

(그림 4)를 보면 AutoEncoder와 Skip-connections를 사용한 AutoEncoder 모델 각각 Identity mapping을 방지하기 위해 넣어준 Stain noise model과 아무것도 안넣어준 경우의 reconstruction image의 결과를 비교한 그림입니다. None의 경우 Identity mapping이 이루어져서 입력 이미지 그대로 출력되어 제대로 결측인 부분들은 감지하지 못합니다. 그러나 Stain noise model을 추가한 결과를 보면 Identity mapping을 방지해서 결함이 있는 이미지가 들어오더라도 구조는 동일하게 가지만 정상인 이미지로 reconstruction하는 것을 볼 수 있습니다. 다만 skip connections을 사용하지 않아서 AE기반인 모델들은 이미지가 blurry하게 나오는 것을 볼 수 있습니다.
AESc를 보면 AE와는 다르게 image가 선명하게 복원되는 것을 볼 수 있으며 Stain model을 사용한 결과가 Identity mapping이 안이루어진 모습을 확인할 수 있습니다.
Train 과정에서 있는 중요 내용들을 다시 한번 요약해보도록 하겠습니다.
- GAN의 mode collapse 문제로 AutoEncoder 구조를 사용해서 Normal Image를 reconstruction 하도록 진행.
- AE는 Bottleneck 구조를 갖는다. 따라서 Feature map을 압축하는 과정이 Normal Image Manifold에 놓여지도록 reconstruction을 일반화 시킬 수 있다.
- AutoEncoder만 사용하면 Identity mapping이 발생되므로 Stain noise model을 사용했다.
- AutoEncoder에 Skip-connections을 추가하므로 써 reconstruction image가 blurry하게 복원 되는 것을 방지했으며 U-Net과의 차이점은 concatenation 말고 Addition 시켜주었다는 점이다
4. Test Step
[Red box]
red box에 있는 내용은 test data를 이용해서 inference하는 과정입니다. 여기서 눈여겨 볼 점은 inference할 때 두가지의 전략(Residual-based detection과 Uncertainity-based detection)으로 진행 했습니다.
4-1. Residual-based Detection
Test과정 중 Query image랑 Query image를 기반으로 Clean(Normal) image로 reconstruction된 image와 차이를 계산하는 것 입니다. 이때 사용되는 loss는 L2Norm(MSE)이고, Image-wise 관점과 Pixel-wise 관점에서 이루어 집니다.
• residual(잔차)
→ 모집단에서 추출한 표본둘의 평균(표본평균)과 개별 표본갑 간의 '편차'를 말하지만 주로 '추정오차 (Estimation Error)'와 거의 같음 의미를 지닌다.
• 추정 오차 (Estimation Error)
→ 표본 집단에 기초해 산출된 기대값(추정값)과 확률 시행 결과의 관측값 과의 차이.
Residual-baded detection의 단점과 MCDropout 사용 이유
Anomaly Detection 하고싶은 부분 말고 나머지 뒷 배경과의 대조가 명확하지 않은 경우. Normal Image로 Reconstruction을 해도 reconstruction loss가 충분하게 높지 않게 됩니다. 따라서 MCDropout을 사용해서 prediction uncertainity을 정량화 하여 anomaly detection에 사용합니다.
4-2. Uncertainty-based Detection
Uncertainity-based detection 방법은 Bayesian Estimation에서 나온 개념입니다. Uncertainty(불확실성)는 확률 변수의 분산 크기이며 확률 변수가 얼마나 random한지 측정하는 sclar 값 입니다. 그래서 해당 값은 Bayesian Model을 이용한 Estimation에서 확인할 수 있는데 Bayesian Model의 parameter 수가 많아서 model이 많이 무겁다고 합니다. 그래서 이와 비슷한 효과를 주는 방법에서 Uncertainity를 정량화 하는 방법으로 MCDropout(Monte Carlo Dropout)을 사용해서 Uncertainity를 정량화 한다고 합니다.
그래서 MCDropout으로 추정한 30개의 output image 사이의 variance(분산)으로 추정할 때 훈련중에 볼 수 없는 structures, 즉, 이상징후가 더 높은 불확실성(uncertainties)과 상관성을 갖는 직관에 의존하는 방법입니다. 그래서 해당 논문에서는 AutoEncoder의 layer가 깊어질수록 dropout level 을 증가하면서 [0, 0, 10, 20, 30, 40] 적용한 결과 더 정확한 검출이 얻어지는 것을 밝혀냈다고 합니다.
(그림 5)는 reconstruction residual가 대부분 uncertainty와 상관관계가 있음을 보여주는 그림 입니다.

(그림 5)를 보면 첫번째, 두번째 행은 Stain noise model을 사용하지 않고 AE and AECs networks를 학습한 경우이고 세번째, 네번째 행은 Stain noise model을 사용한 경우입니다. 두가지 경우 공통적으로 test 할 때 MCDropout을 사용 안한 상태로 Residual-based detection과 Uncertainty-based detection한 결과를 나타내고 있습니다.
데이터셋 상황에 따른 Detection 방법 선택
Residual-based Detection은 Reconstruction error threshold를 넘어가면 결함으로 간주하는 원리입니다. AECs가 Normal 한 이미지를 reconstruction을 하도록 학습하는 과정은 결함이 있는 구조를 깨끗한 이미지로 대처하도록 하는 것이 목적이지 그 주변 환경과의 대비를 더 명확하게 주라고 학습을 한 것은 아닙니다. 그래서 reconstruction image가 주변 환경과 대조가 잘 되지 않으면 residual intensities가 낮게 나옵니다.
반면에 Uncertainity-based Detection은 이미지의 구조와 주변 환경의 대비에 의존하지 않는다는게 가장 큰 특징입니다. 따라서 대비가 늦은 결함 이미지의 경우 Anomaly Detection 기능이 향상됩니다.
정리를 한번 해보도록 하겠습니다.
주변환경과 데이터셋 대비가 명확하다
→ Residual-based Detection 전략이 좋다.
주변 환경과 데이터셋 대비가 명확하지 않다.
→ Uncertainity-based Detection 전략이 좋다.
추가적으로 위에서도 언급했다 싶이 Residual-based Detection 전략으로 진행할 경우 AESc + Stain model은 일반적으로 산발적인 반점으로 구성 된 reconstruction residual을 유발하고 낮은 대비를 갖는 데이터셋에 대해 결함을 놓치게 된다. 이런 경우에는 Uncertainity-based 전략이 효과적이다.
5. Conclusion
Query image에서 Normal image를 reconstruction 하는 것을 기반으로 한 anomaly detection 방법을 진행하기 위해서 본 논문에서는 Skip-connection을 사용한 AutoEncoder인 AESc를 기반으로 MCDropout으로 30번 estimated된 reconstruction residual 또는 prediction uncertainity에 의존하여 Anomaly Detection을 진행합니다.
Skip-connections를 Addition 시켜 사용한 AutoEncoder 구조를 사용할 때 장접을 본 논문에서는 입증을 하였으며 Identity mapping이 이루어지지 않도록 train image가 Stain Noise model로 corrupted 시켜서 학습을 진행하였습니다.
또한 본 논문에서 사용된 새로운 접근 방법은 일반 AutoEncoder보다 상당히 잘 MVTec AD Dataset들의 결함들을 잘 검출 해냈으며 AECs + Stain noise model을 사용하여 AutoEncoder와의 Uncertainity-based Detection 전략을 공정하게 비교해냈습니다.
Reconstruction residual과 달리 Uncertainity Indicator는 결함과 그 주변 사이 환경의 대비와는 무관합니다. 따라서 주변 환경과 대비가 뚜렷하다면 Reconstruction residual 전략으로 가고 대비가 뚜렷한 대비가 없다는 Uncertainity 기반 전략으로 Anomaly Detection을 진행하면 됩니다.
또한 Residual-based detection 전략에 비해 Uncertainty-based detection 전략은 Normal한 query image에서 false-positive rate를 증가키시게 되는 단점이 존재합니다.



