
티스토리 뷰
[PGGAN] Progressive Growing of GANs for Improved Quality, Stability, and Varation
Waterbottle 2019. 12. 20. 21:421. Abstract
1-1. Problem
PGGAN(Progressive Growing of GANs)은 2017년도에 나온 Nvidia에서 나온 논문이고 발표 당시 큰 이슈를 받았다고 한다. 그 이유는 그 전까지 GAN들은 고해상도(High resolution) 이미지를 만드는것이 매우 힘들었는데 이 논문이 새로운 접근 방법으로 고해상도 이미지 생성하는 것을 해결했다.
일반적인 GAN으로 고해상도 이미지를 만든다고 한다면, 아래와 같은 문제들이 발생을 할 것 이다.
- 고해상도 이미지를 만드는 것은 매우 어려운 일이다. 그 이유는, High Resolution 일수록 Discriminator는 Generator가 생성한 Image가 Fake Image인지 아닌지를 구분하기가 쉬워지기 때문이다.
- 고해상도 이미지를 잘 만든다고 해도, 메모리 제약 조건 때문에 mini-batch size를 줄여야 한다. batch size를 줄이면 학습과정 중 학습이 불안정해지는 현상이 발생하게 된다.
위와 같은 이유때문에 기존 GAN같은 방법(DCGAN 등..)으로는 고해상도 이미지를 생성해내지 못하는 단점이 있다.
1-2. Approach
이 논문에서 제안하는 Key Point는 점진적으로 Generator와 Discriminator를 키우는 것이 핵심 포인트이다. Low resolution 에서 High resoliution으로 키우기 위해서 layer를 점진적으로 add해주는 것이다. 이렇게 점진적으로 layer를 추가해서 학습을 해주는 과정을 통해서 점점 High Resolution image를 만들어내게 된다.(해당 논문에서는 이와 같은 방법으로 1024x1024 image를 generator했다고 나와있다.)
2. Progressive Growing of GANs
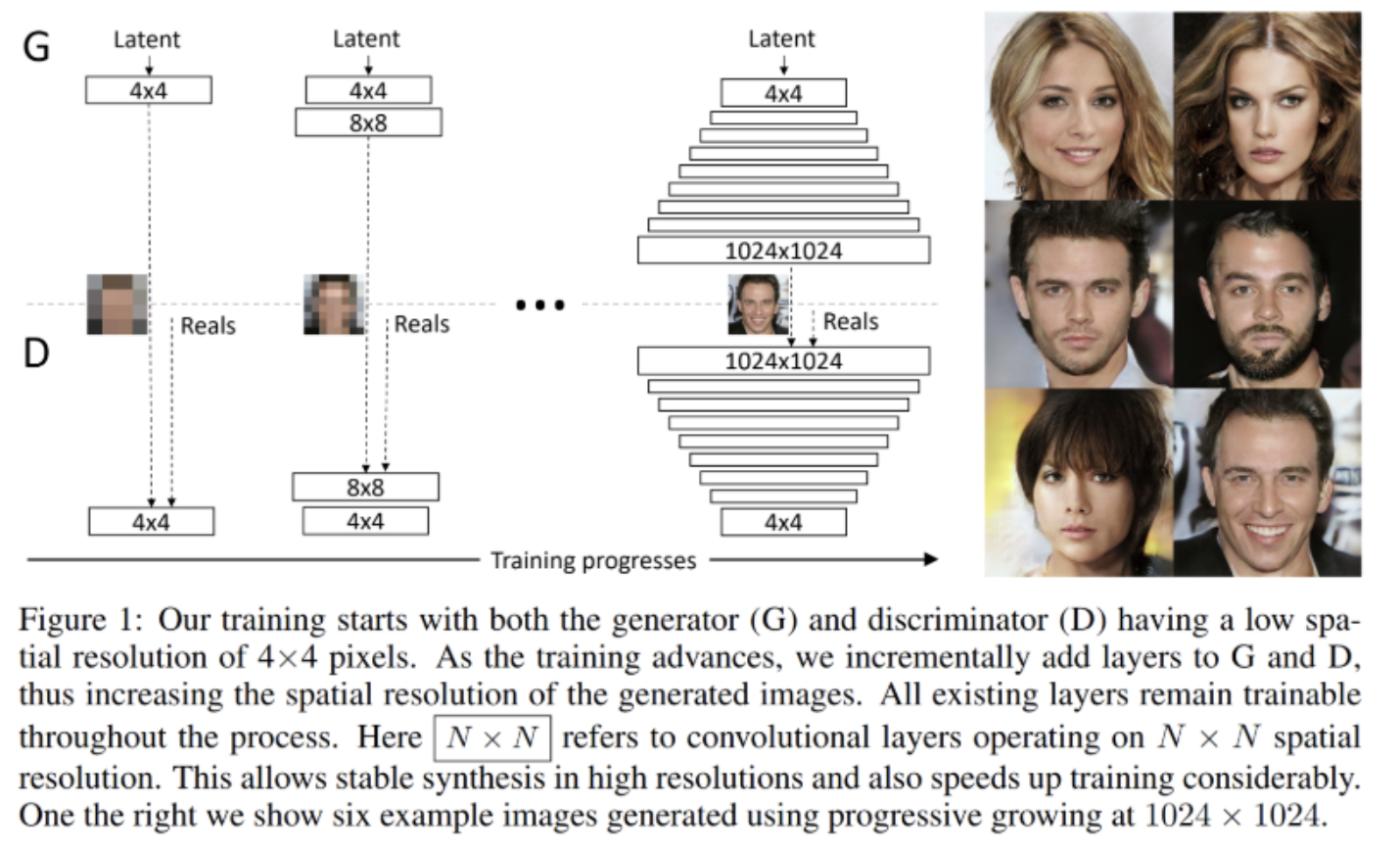
2-1. 점진적으로 layer를 add해서 학습을 할때의 장점은?
Image Distribution(각 이미지마다 분포가 다 다르다)에서 Large scale 구조를 먼저 발견하도록 도움을 준다.
Large Scale이란?
CelebA라는 사람 얼굴에 대한 Dataset이 있다고 하자. 이 데이터셋에서 Large Scale이란 전반적인 전체 얼굴의 형태를 의미한다.
즉, 해당 논문의 Key Point는 "G와 D의 모델을 점진적으로 쌓아 올려가며 학습을 하는 것"이다. 맨 처음에는 저해상도 이미지에서만 보여질 수 있는 Feature인 Large Scale들을 보면서 사람 얼굴에 대한 전반적인 내용들을 학습을 진행하고 점차 레이어를 쌓아 올라갈수록 세부적인 Feature들(눈, 코, 입, 모공, 머리카락, 눈꼽(?))들을 보면서 학습을 진행해나아간다.
여기서 주의할점은 모든 Large Scale를 동시에 학습을 하는것은 아니다. 아래 그림을 보면 더 자세히 알 수 있을것이다.
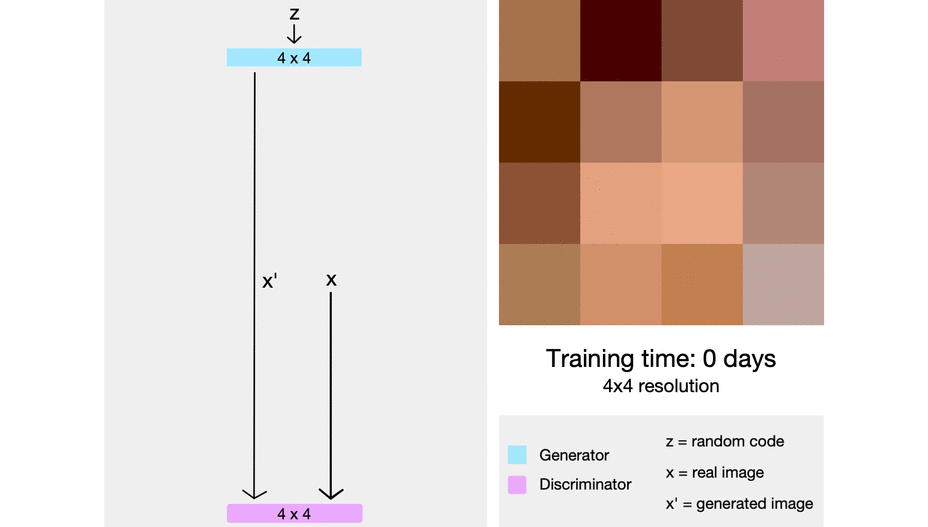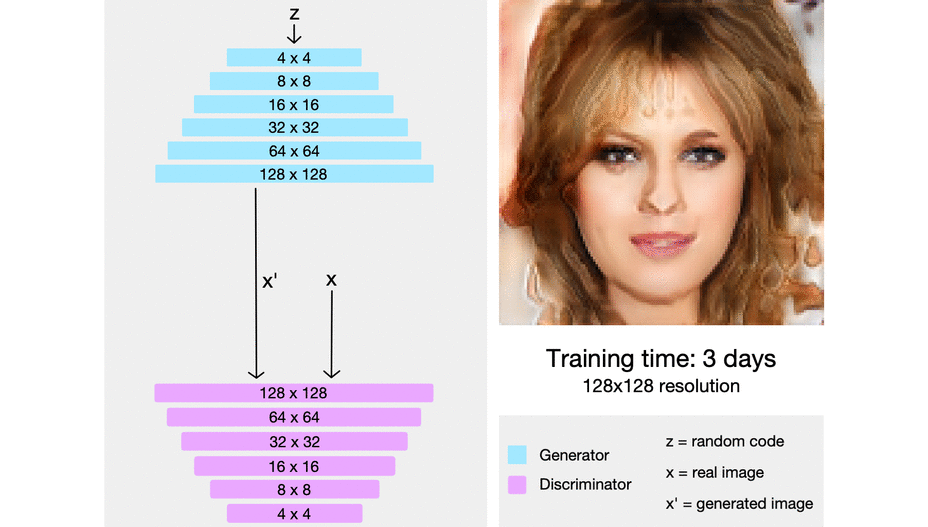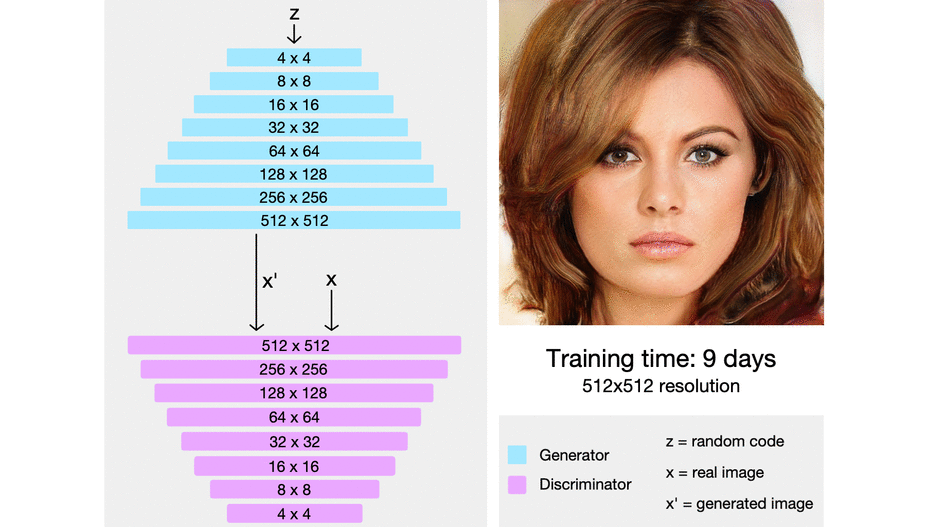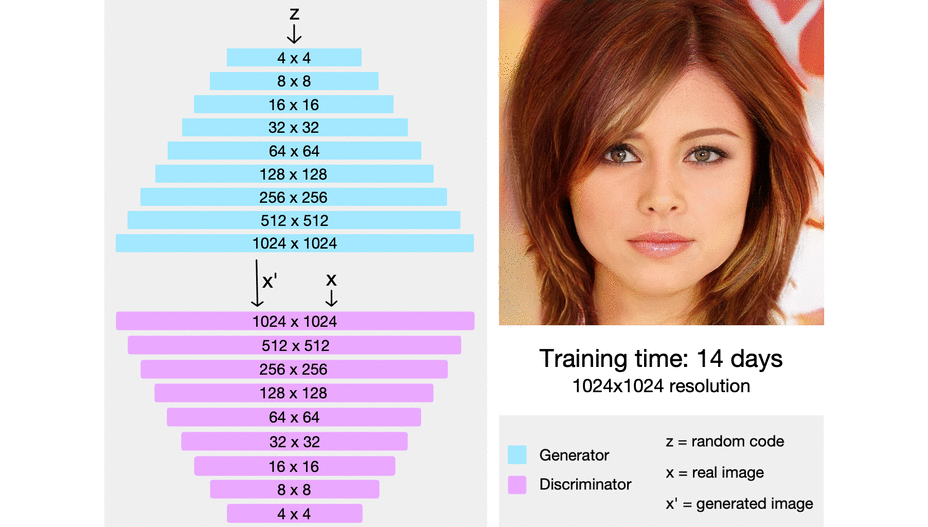
해당 논문에서는 점진적으로 Model에 layer를 추가할 때 새로 추가하는 레이어를 smooth하게, fade in 하게 넣어준다고 한다. 이 말은, 이미 잘 학습된 이전 단계의 layer( n-1 layer)들에 대한 sudden shock를 방지한다고 한다.
!. 나의 생각이지만... DCGAN에서도 'walking in the space' 라는 개념이 있다. 그거랑 비슷한 개념이지 않을까 싶다.
다음 그림은 PRGAN의 학습 방법을 좀 더 상세하게 나타내는 그림이다.
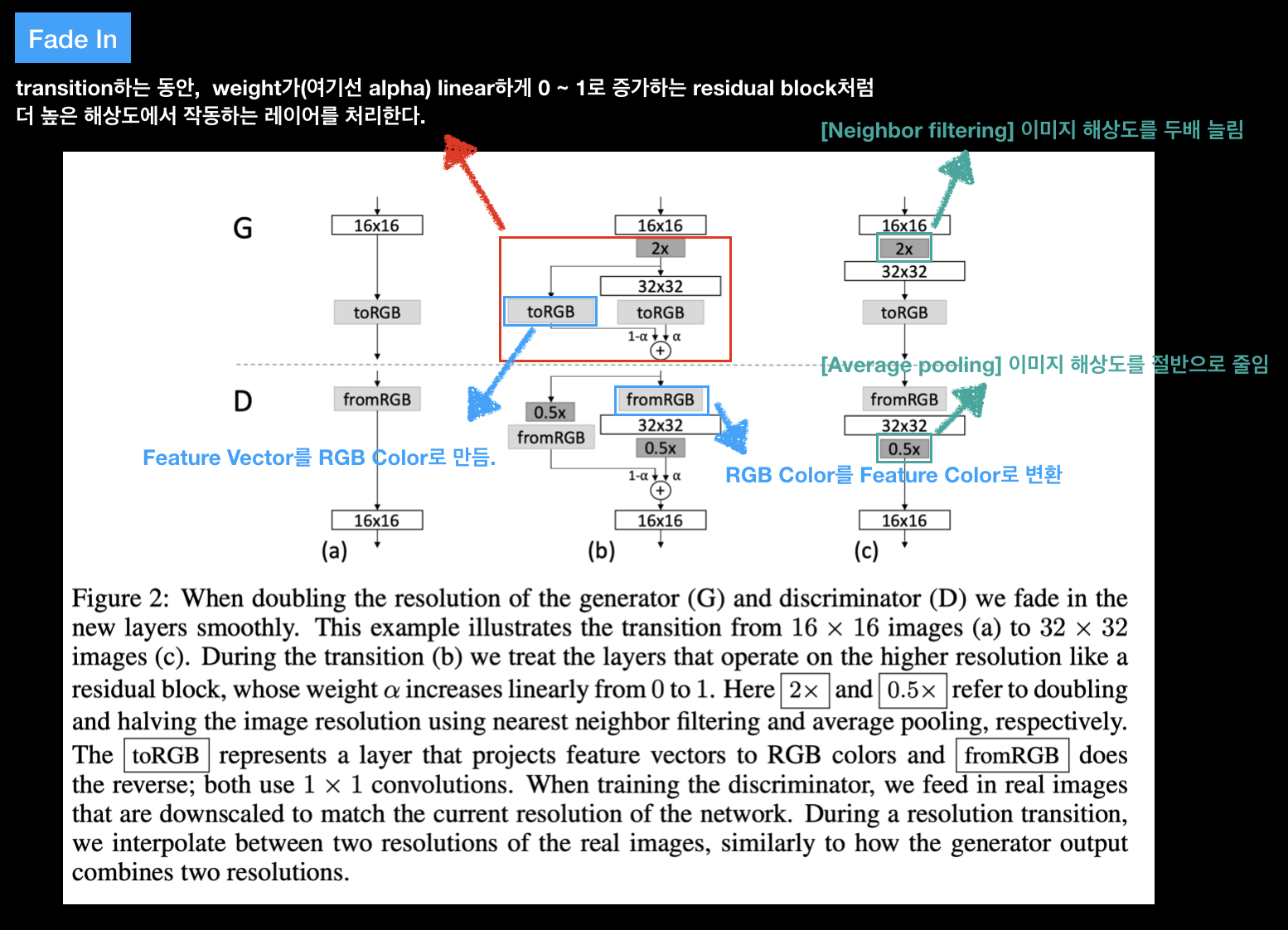
위와 같은 학습 방법에 대한 장점으로는 다음과 같다.
- 점진적으로 layer를 쌓아가며 학습하는 방법은, 학습이 안정적으로 된다는 장점이 있다.
- 또한 점진적으로 layer를 쌓아가며 High resolution 이미지를 생성해내는 방법은, Resolution 에 맞게 latent vector가 mapping 되면서 학습된다는 장점이 있다. 그래서 안정적으로 고해상도 이미지를 만들어낼 수 있다.
==> 이러한 학습을 하기 위해서는 WGAN-GP Loss를 적용해야 한다.
- 학습 시간이 절약된다( 이건 잘 이해가 안되는데 논문에서는 그렇다고 한다...)
2-2. 학습 방법
Generator

해당 과정을 이해하려면 우선적으로 알고 있어야하는 사전지식들이 있다. 그 지식들에 대해서 먼저 알아보도록 하겠다.
UpScaling
바로 예시를 들어서 설명을 하도록 하겠다. TV에서 방송 영상을 볼때 일반영상을 UHD급 고화질 화면으로 시청을 할 경우 가로-세로의 pixel들을 다 채워주지 못해서 화면이 뿌옇고 흐리게 보이게 된다. 이러한 문제를 upscaling으로 해결을 할 수 있는데 이는 부족한 pixel들을 채우므로서 더 선명하게 보여주도록 하는 것이다. (이런 과정을 하려면 DownScaling을 우선적으로 해야하는데 관련 내용은 Discriminator 부분을 설명할때 언급하도록 하겠다.)

이런 Up-Scaling하는 block을 각 Layer 맨 앞단에 위치시켜서 UpScaling 해주는것을 볼 수 있다.
Fade in
transition하는 동안(G에서는 Up Scaling, D에서는 Down Scaling) weight(=alpha)가 linear하게 0 ~ 1로 증가하는 residual block처럼 안정화 하기 위해서 alpha값에 의해 제어가 된다.따라서 새로운 layer가 완전히 학습이 안정적으로 될 때 까지 linear하게 0 ~ 1 사이의 값으로 증가하게 된다.
해당 개념은, Generator와 Discriminator에 둘 다 적용이 되는 개념입니다.
Normalization in Generator and Discriminator
일반적으로 Gan은 Generator와 Discriminator간의 불필요한 경쟁으로 인해 escalation of signal magnitudes(훈련 중 신호 크기가 제어를 벗어나는 것)이 있다. 이를 억제하기 위해서 Batch Normalization 방법이 사용되었는데, 이 방법은 Convariate shift 현상을 제거하기 위해 도입된 방법이다. 그치만 해당 논문에서는 Covariate shift 문제는 발생이 안되므로 Batch Norm을 사용 안했다.
그렇다면 여기선 어떤 Normalization을 사용했는지 궁금해질텐데 바로 아래에 정리되어있는 Pixelwise feature vector normalization 을 이용해서 escalation of signal magnitudes 문제를 해결햇다.
Pixelwise Feature Vector Normalization
일반적으로 딥러닝에서 많이 사용되는 normalization 벙밥 중 하나가 Batch Normalization이다. 그렇지만 이 논문에서는 Batch normalization을 사용하는것이 효과가 없다고 한다. 그래서 사용한 방법이 Pixelwise normalization이다. 말 그대로 pixel 단위 별로 normalization해주는 것 이다. 이 방법을 좀 더 디테일하게 설명을 하자면 각 Pixel 별로 Feature Vector를 단위 길이(unit of length)별로 Normalization을 해주고, 각 Layer 맨 뒷 단에 적용을 해주면 된다.
해당 Normalization 개념은, Generator의 Upsampling 할때만 적용이 되는 방법이다.
그렇다면 왜 굳이 Batch Normalization을 사용 안하고 Pixelwise Normalization을 사용하는 것 일까? 그 이유는 아래와 같다.
Generator와 Discriminator가 경쟁의 결과로 magnitudes가 통제 불능이 되는 것을 방지하기 위해서 사용되는 기법이라고 한다.
좀 더 자세히 알애보면 각 Convolution layer의 Feature layer에 대한 Pixel wise로 normalizaing 해주는 것이며 local response normalization을 변형해서 구현한 것 이다.
해당 방법은 결과물에 변화는 크게 없지만, escalation of signal magnitudes(훈련중에 신호 크기가 제어를 벗어나는 것)를 효과적으로 방지한다고 알려져 있다.
Pixelwise Feature Vector normalization은 N채널에 걸쳐진 각 Pixel (x, y)의 값은 고정 길이(fixed length)로 Normalization 된다.

class PixelNormLayer(nn.Module):
def __init__(self):
super(PixelNormLayer, self).__init__()
def forward(self, x):
return x * torch.rsqrt(torch.mean(x ** 2, dim=1, keepdim=True) + 1e-8)
def __repr__(self):
return self.__class__.__name__Discriminator

Discriminator도 마찬가지로 이 내용을 이해하려면 사전에 미리 알고 넘어가야할 개념들에 대해서 먼저 알아보도록 하겠다.
DownScaling
Low resolution에서 High resolution의 information을 유추하는 절차라고 볼 수 있다.

실제 training을 하는 과정을 step by step으로 한번 알아보도록 하자.
[step 1]
Network의 현재 해상도에 맞춰서 real images(우리가 가지고 있는 training data)를 Downscaling 하여 넣어준다. 그러면 저해상도 이미지로 변경이 되긴 하지만, 고해상도 이미지에 대한 정보를 담고 있다.
[step 2]
Resolution transition하는 중에는 Real image의 두개의 해상도 사이(n-1 layer와 앞으로 쌓을 n layer 사이)를 interpolation(선형 보간)한다. 논문에서 해당 과정은 Fade in 과정으로 설명이 되어있다. (그림 2-3의 붉은색 화살표에 대한 내용이다.)
Increasing Variation using MiniBatch Standard Deviation(표준 편차)
본 포스트 초반에도 언급이 된 내용이지만 다시 해당 개념을 설명하기에 필요한 내용이므로 간략하게 다시 언급하고 넘어가도록 하겠다. 일반적인 GAN의 특징으로 훈련 중 train data에서 찾은 Feature Information보다 less variation(변화도가 적은)한 generator image를 생성해내는 경향이 있다. 그로 인해서 고해상도 이미지를 생성해내기 어렵다는 단점이 발생되게 되는데, 이를 해결하고자 PGGAN에서는 Minibatch Standard deviation 방법을 제안을 하게 되었다.
Minibatch standard deviation이란, Feature statistics를 계산할 때 각각 한장의 이미지들만 보는 것이 아니라, mini batch로 묶여진 전체 배치 이미지에 대해 계산을 해서 Generator에 의해 생성된 Fake image와 training될 Real train image data들의 비슷한 statistics를 갖도록 하는 방법이다.
그렇다면 여기서 궁금한점이, 일반적인 GAN의 문제를 해결하고자 mini-batch standard deviation 방법을 제안했는데 이걸 왜 굳이 하는지가 궁금해졌다. 그래서 조사를 해보았고 그 해답은 아래와 같다.
Discriminator가 Mini Batch 전체에 대한 Feature statistics를 계산하도록 해서 Real train image data와 Fake batch image를 잘 구별해내도록 도움을 줄 수 있어서 사용하는 것 이다.
또한, 생성된 배치 이미지에서 계산된 Feature statistics가 training된 batch iamge data의 statistics와 더 유사하게 만들도록 Generator가 less varation을 갖는게 아니라 더 풍부한 varation한 것을 생성해내도록 권장하기도 한다.
Equalized Learning Rate(runtime weight scaling)
저자는 Generator와 Discriminator 사이의 helthy한 경쟁(?)을 보장하기 위해서 layer가 비슷한 속도로 학습하는것이 필수라고 말을 했습니다.(그냥 잘 학습이 되기 위해서는 learning가 비슷해야 잘 된다 라고 보면 될거 같습니다) 그래서 이 논문에서 제안하는 방법이 Equalized Learning Rate 접근법을 제안했습니다. 우선 이 방법은 초반 Weight Initialization을 Gaussian Distribution으로 0 ~ 1의 rage를 갖는 값으로 Initialization을 해줍니다.
모든 Weight들에 대해서는 동일한 Dynamic range를 갖도록 지정해줍니다. 이렇게 해주는 이유는, 보통 parameter의 scale과 무관하게 Gradient를 update를 해주게 됩니다. 이때 parameter마다 dynamic range가 다 다르면 이 값을 조절하는데 시간이 많이 소요가 되게 됩니다. 따라서 저자는, Equalized Learning rate 접근 방법을 사용해서 각각 다른 layer들의 parameter(weight)들에 대해 동일한 dynamic range를 갖도록 하여 동일한 학습 속도를 보장하도록 했습니다.
이 방법은 He initializer를 사용하면 됩니다.
class WScaleLayer(nn.Module):
def __init__(self, incoming, gain=2):
super(WScaleLayer, self).__init__()
self.gain = gain
self.scale = (self.gain / incoming.weight[0].numel()) ** 0.5
def forward(self, input):
return input * self.scale
def __repr__(self):
return '{}(gain={})'.format(self.__class__.__name__, self.gain)
'Python > 머신러닝&딥러닝' 카테고리의 다른 글
| Pytorch 코드 작성 팁 (0) | 2020.04.12 |
|---|---|
| [StyleGAN] A Style-Based Generator Architecture for Generative Adversarial networks (0) | 2020.03.12 |
| [AnoGAN] Unsupervised Anomaly Detection with GAN 정리 (0) | 2019.11.05 |
| [GAN] Generative Adversarial Network 정리 (0) | 2019.10.17 |
| (Tensorflow_eager)Mnist와 AlexNet을 이용한 CNN (0) | 2019.07.21 |


