
티스토리 뷰
1. 퍼셉트론이 무엇인가?
가장 간단한 Artificial Neural Network의 기본 구조이다. 앞으로 Deep learning에 대해 공부를 하기 전 퍼셉트론에 대한 개념을 확실하게 잡아야 나중에 도움이 된다.
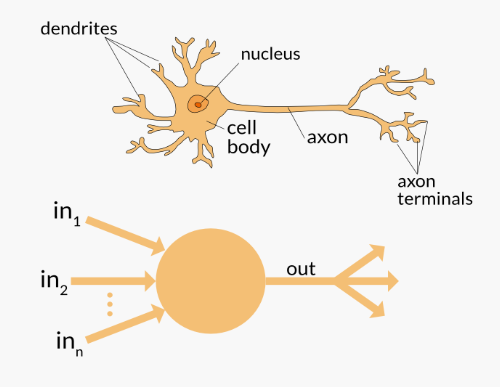
앞으로 언급할 퍼셉트론에 대한 개념은 생물학적인 뉴런과 밀접한 관계가 있다. 생물학적인 Neuron을 보면 (1) dendrites로 모든 신호를 받아드리고 (2) cell body에서 신호를 모은 후 (3)axon을 통해 신호가 잘 갈 수 있도록 채찍질 해주고 (4) axon terminals로 다음 neuron으로 신호를 전달하는 구조이다.
퍼셉트론은, 생물학적인 neuron에서 이루어지는 과정을 수학적으로 모델링한 인공뉴런이다. 퍼셉트론의 입력을 Xi라 하고 시냅스의 가중치를 W라고 하면 퍼셉트론의 가중치를 곱한 입력의 합 Y는 아래와 같이 계산이 된다.

오래전부터 어떤 데이터들은 적절한 Decision Boundary(경계선)를 통해서 분류하는 알고리즘을 개발했다. 그 중 하나가 바로 Neuron(=Node)이다.
※ Neuron 하나를 Decision Boundry 하나라고 봐도 무방하다.
2. 퍼셉트론의 구조
*이번 게시물에서 Activation Function은 Step Function(계단형 모양)으로 정의를 하겠습니다.

구조는, inputs 마다 weight들이 곱해지고 그것을 더한 다음 threshold(한계점)값에 따라 output이 나오는 형태이다.
1) Weight(가중치)란?
결과에 있어서 어떤 input이 가장 영향력이 있는지 알려주는 기준이 되는 값

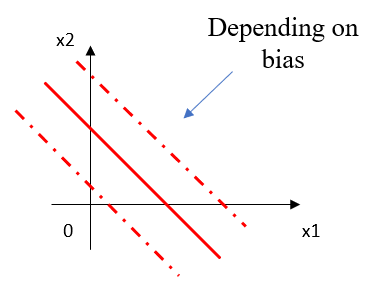
2) Bias(편향)란?
Decision Boundary의 수평적으로 위치를 변경하는 역할을 하며, bias가 변경된다는 것은 Decision Boundary의 위치가 변경된다는 것을 의미한다.
3) 나머지 기본 내용
나머지 기본 내용들(다층 퍼셉트론 등)은 다른 블로그가 더 자세히 나와있으니 다른 블로그를 참고해주시기 바랍니다.
(사실 포스팅하기 귀찮아서..)
3. 세미나 하면서 알게된 내용
1) 레이어를 Deep(깊게)하게 쌓는것은 좋은것인가??
어떤 모델이든 깊게 쌓으면 쌓을수록 더 표현력도 많아지고 좋아지는것은 사실이다. 그러나 무조건 깊게 쌓는다고 좋은것은 아니다. 터무니 없이 계속 깊게 쌓으면 Overfitting(과적합) 현상이 발생하게 된다. 그래서 새로운 데이터를 넣어도 제대로 Classification이 잘 안이루어지기 때문에 Artificial Nerual network(인공신경망)을 구성할때는 overfitting이 발생하지 않도록 조절하는 능력이 필요하다.
2) Layer를 Deep하게 쌓을수록 Overfitting이 발생한다고 위에서 그랬는데, 그러면 Overfitting을 방지하기 위해서 Deep하게 안쌓으면 다 해결되는게 아닌가?
Deep하게 안쌓으면 우리가 흔히 말하는 Deep Learning이라는 개념도 없었을 것이다. 그러나 Deep Learning을 많이 사용하고 많이 공부하려고 하는 이유는 분명히 있다.
우선 깊게 쌓는다는 의미는 Layer의 갯수가 많아진다는 것이고, 여기서 Layer는 차원을 의미한다. 그래서 1층으로 구현된 Layer는 1차원, 2층으로 구현된 Layer는 2차원, 3층으로 구현된 Layer는 3차원,... n층으로 구현된 Layer는 n차원으로 깊게 쌓으면 쌓을수록 우리가 말로 설명할 수 없을 정도로 고차원이 되버리고 그 고차원 내부에서 그만큼 표현할 수 있는 내용들이 많아지니까 깊게 쌓을수록 표현력이 많아진다고 하는 것이다.
실제 구현을 할때 Leyer를 얼마나 깊게 쌓을것인지 생각을 하게 된다면, 처음에는 Complexity(복잡성)를 크게하고(이때는 분명 Overfitting이 발생하게 될 것이다.) 데이터를 넣어가면서 점차 complexity를 조절하는 방식으로 나아가야한다.
3) 왜 overfitting이 일어나는가?
실제로 우리는 구현을 할때 완벽한 raw input data를 가지고 있지 않은게 현실이다. 따라서 Deep하게 모델을 쌓는다는 것은 Complexity가 많아진다는 이야기이고 이는 훈련시켜야할(Optimization을 시켜야할) Weight수가 많아진다는 것이다. 만약 데이터가 이상적으로 많다고 가정한다면 전부 훈련을 시켜서 제대로된 Decision Boundary로 input space를 잘 나눌 수 있지만, 실제로는 한정된 데이터를 가지고있다보니까 한정된 데이터에 Decision boundary가 맞춰지는 것이다. 따라서 특정 데이터셋으로만 훈련을 시키면 해당 훈련된 데이터에만 fitting하게 학습이 되게 된다. 따라서 Overfitting이 발생되게 된다.
그래서 훈련을 하기 전에 내가 표현하고자 하는 것을 충분히 표현할 수 있을 만큼 데이터가 많은지 우선적으로 생각하고 Complexity를 어느정도로 할 것인지 생각해야 한다.
4) Feature Hierarchy

Medical Image에서는 보통 선(edge)을 Feature로 뽑아내고 그 다음은 더 고차원적인 Feature를 뽑아내고 나중엔 모양을 형상하게 된다. 이러한 방식을 Feature hierarchy이라 하며 해당 개념은 Deep learning에서 매우매우매우 중요하다. Feature Hierarchy의 개념을 가지고 Deep Learning을 공부하게 되면 왜 깊게 쌓는지 그 이유를 할 수 있다. Deep Neural network에서는 선(1차원), 평면(2차원), 부피(3차원), n차원의 공간을 이용해서 Decision Boundary를 찾아내기위해 깊게 쌓는것이다.
4-1) Decision Boundary의 차원은 무엇에 의해 결정되는가??
기본적으로 여기서는 input이 정해지면 그 input을 나누기 위해 Decision Boundary를 정하는 거고 Decision Boundary 차원은 그 공간을 나누는 Plane 하나가 정해지는거고, 그 Plane은 input 차원에 의해서 결정되는 것이다. 따라서 다음 차원(n+1)은 이전 공간의 feature에 따라서 정해지는 것이다.
*TIP : Input space가 n차원 이라면, 거기서 선을 긋는 Decision Boundary는 무조건 n-1차원이다. 예를 들어서 3차원의 공간을 Decision Boundary로 나누면 2차원의 공간이 되는것이다.
Decision Boundary 개념 참고 링크 : Applied Deep Learning - Part 1: Artificail Neural Networks
'Python > 머신러닝&딥러닝' 카테고리의 다른 글
| [Kaggle] Attention on Pretrained-VGG16 for Bone Age_전처리 과정 (1) | 2019.05.19 |
|---|---|
| 딥러닝 필수 기본 개념 (0) | 2019.05.19 |
| ch04. 신경망 학습(밑바닥부터 시작하는 딥러닝) (0) | 2019.03.30 |
| [실습]언어구분학습_1 (0) | 2018.02.18 |
| [실습] 붓꽃 품종 분류를 해보자 (0) | 2018.02.11 |


