
티스토리 뷰
[CycleGAN] Unpaired image-to-image Translation using Cycle-Consistent Adversarial Networks
Waterbottle 2020. 8. 18. 16:101. Abstract
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be available. We present an approach for learning to translate an image from a source domain X to a target domain Y in the absence of paired examples. Our goal is to learn a mapping G : X → Y such that the distribution of images from G(X) is indistinguishable from the distribution Y using an adversarial loss. Because this mapping is highly under-constrained, we couple it with an inverse mapping F : Y → X and introduce a cycle consistency loss to enforce F(G(X)) ≈ X (and vice versa). Qualitative results are presented on several tasks where paired training data does not exist, including collection style transfer, object transfiguration, season transfer, photo enhancement, etc. Quantitative comparisons against several prior methods demonstrate the superiority of our approach.
2. 사전지식
2-1. GAN
Image-to-Image translation tasks 관점에서 보면 흑백 이미지 사진을 컬러 사진으로 변경 해주는 경우 Generator는 이미지를 실제와 비슷하고 선명하게 생성을 해주는 것이 목적 입니다. 즉, GAN은 이미지의 detail을 담당한다고 볼 수 있습니다. Discriminator는 Generator가 이쁘게 만들어낼 수 있도록 선생님 역할을 담당하여 Generator의 training을 도와주는 역할을 하게 됩니다.
참고 블로그: [GAN] Generative Adversarial Network 정리
2-2. Pix2Pix
Pix2Pix는 GAN의 개념에다가 Image difference 개념을 추가한 것 입니다. 자세한 내용을 이전에 정리했던 블로그 글을 참고해주시기 바랍니다.
참고 블로그: [Pix2Pix] Image-to-Image Translation with Conditional Adversarial Network
3. CycleGAN
3-1. 목표
🤜 주어진 dataset이 동일한 구성요소(composition)는 아니고 각각 다른 Style인 경우(=Unpaired Image) 그럴듯한 Image translation을 해보는 것.
🤜 Generator가 그림 → 사진 으로 변경할 때 다시 사진 → 그림 으로 복구가 가능한 정도로 바꾸는 것.
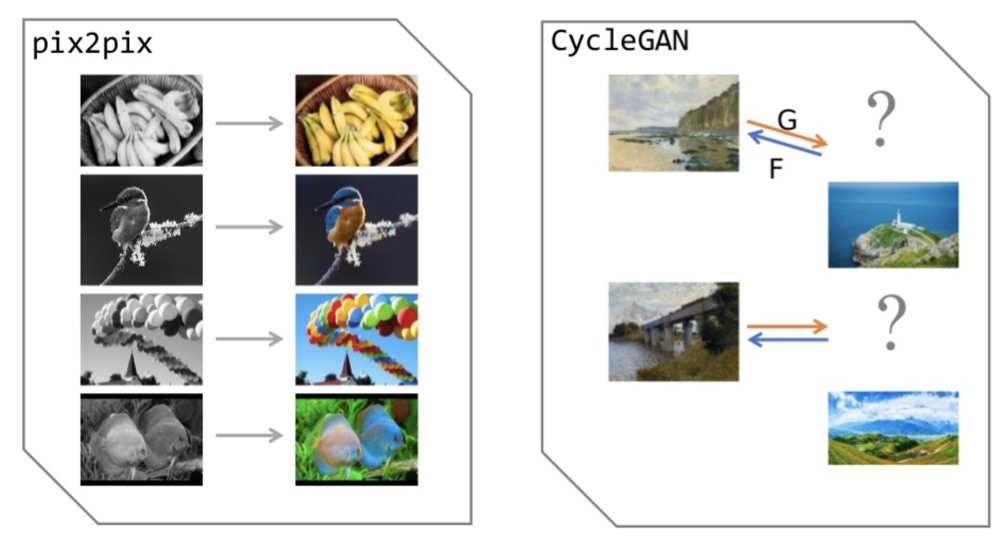
CycleGAN과 Pix2Pix의 차이점은 생성된 이미지를 다시 원래 이미지로 복구 가능한지 아닌지 입니다. CycleGAN을 공부하다가 든 생각인데, 단순하게 생각을 해보면 Pix2Pix model을 두개 만들어서 A ←→ B 가 가능하도록 해도 될것을 Cycle이라는 개념을 추가하여 CycleGAN이라는 모델을 제안한 것은 그 당시 기발한 아이디어라고 생각이 들었습니다.
이 부분에서 저와 같은 생각이 드신 분들도 많으실거라고 생각을 합니다.
두 모델(Pix2Pix & CycleGAN)의 목표는 Image-to-Image translation입니다. 그렇다면 Pix2Pix에서 사용한 GAN Loss를 CycleGAN에 적용해보면 어떻게 학습이 이루어지는지 알아보도록 하겠습니다.
🤔 Pix2Pix GAN Loss를 CycleGAN에 적용하면 어떻게 될까?
👉 Generator이 생성해낸 G(z)가 Discriminator를 속이면(실제 training data와 비슷하게만 보이면 됨) 일반적인 GAN의 역할을 하는 것 이니 적용은 가능합니다. 그러나 다른 부작용이 발생합니다.
❗️ [부작용] 입력으로 사람 이미지가 주어졌다고 생각 해보면, Pix2Pix에서 사용한 GAN Loss를 이용해서 학습한 CycleGAN은 입력 데이터로 무엇이 들어왔든 무시하고 오직 D를 속이기 위해 가이드 없이 학습을 진행하다 보니 전혀 다른 이미지를 생성해낼 위험이 존재합니다.
🤜 GAN Loss를 사용하면
- 입력 이미지의 Style을 무시하며 학습 할 위험성이 존재합니다.
- 어떤 input data가 들어와도 똑같은 output만 내놓습니다.
이러한 문제로 인해서 CycleGAN에서 Generator은 Discriminator를 속이는 것 뿐만 그림 → 사진으로 바꿀 때 다시 사진 → 그림으로 복구 가능한 정도로 학습은 하는 기능을 담당하는 'Cycle Consistency Loss'를 추가해서 학습을 하게 된다.
Cycle Consistency Loss는 아래 Loss 파트에서 다루도록 하겠습니다.

Pix2Pix와 CycleGAN의 차이점에 대해 간략하게 한번 알아보도록 하겠습니다.
⭐️ Pix2Pix vs CycleGAN
👉 Pix2Pix: G만 학습 시킨다. (Loss는 G에 대한 Loss 1개)
👉 CycleGAN: G랑 F를 동시에 학습 시킨다. (Loss G, F에 대한 Loss 2개)
제 생각이지만... 일반적으로 생각을 해보면 generation image와 input image가 자유롭게 Cycle이 가능하다는 것은 Latent Space가 잘 mapping 된 것이 아닐까? 라는 생각이 들게됩니다. 따라서 mapping이 안되어 있는 흔히 noise라고 불리는 Latent Space 말고 AutoEncoder에 Encoder 부분을 이용하여 Latent Space를 입력 이미지와 Mapping한 후 어느정도 중요한 Feature들을 갖고 있는 Latent Space를 이용하여 GAN 학습을 이어서 하는 방법으로 하면 되지 않을까?? 라는 생각이 들 수 있습니다. (저는 실제로 읽다가 이런 생각이 들었습니다.)
실제로 이러한 방법들은 DiscoGAN(2017), F-AnoGAN(2019) 등 많은 논문에서 적용이 되었습니다. 자세한 내용을 아래에서 다루도록 하겠습니다.
3-2. AE + GAN 구조
AutoEncoder에서 얻은 latent space를 학습으로 이용하는 GAN 구조부터 한번 알아보겠습니다.

해당 구조를 하면 입력 이미지에 대한 중요한 Feature들을 담고 있는 latent space가 존재하고 그 latent space에서 다시 원래 사진으로 돌아가는 구조입니다. (쉽게 생각해서 Generator가 Decoder라고 생각을 하면 좋을거 같습니다.) 이때 latent space를 우리가 눈으로 확인할 수 없다는 것이 큰 특징 입니다.
3-3. CycleGAN 구조

하지만 CycleGAN을 보면 input image가 들어가고 중간에 bottleneck 구조를 띈 latent space가 아니라 실제로 우리가 시각적으로 볼 수 있는 사진으로 되어있는 latent space가 target image로 존재한다고 생각을 하면 좋을거 같습니다.
4. DiscoGAN vs CycleGAN

DiscoGAN은 CycleGAN과 2017년도에 나온 동일한 시기에 비슷한 아이디어로 나온 논문 입니다. DiscoGAN(Learning to Discover Cross-Domain Relations with Generative Adversarial Networks)의 전제 논문 제목을 보시면 "Cross-Domain"라고 나와있습니다. 제목에도 나와있다 싶이 (그림 5) 처럼 Domain이 전혀 다른 이미지로 변형(ex, 가방 → 신발, 자동차 → 사람 얼굴)을 해주는 논문입니다. DiscoGAN의 Generator는 Bottleneck 구조를 갖는 Encoder-Decoder 구조입니다. Encoder-Decoder 구조의 특징은 input image의 중요한 feature들만 추출합니다. 이런 bottleneck 구조를 갖는 model은 Image-to-Image translation에서 형태가 급진적으로 변형되는 현상이 발생되게 됩니다. 마침 DiscoGAN의 목표는 Domain을 변형시키는 것(=형태가 급진적으로 변형)이 목표니까 bottleneck을 갖는 Encoder-Decoder 구조가 적합합니다.
그에 비해 CycleGAN은 Domain을 바꾸는 것이 아니라 형태는 그대로 유지하되 그 Style을 변경하는 것이 목표입니다. 그래서 Bottleneck을 갖는 Encoder-Decoder 구조는 맞지 않습니다. (PixPix 정리글 3-1 참고)
CycleGAN 논문에서는 Encoder-Decoder 구조는 맞지 않으니 skip-connection을 갖는 U-Net Archutecture를 이용해서 CycleGAN의 Generator에 적용을 해보았습니다.
5. Architecture
5-1. Generator
U-Net Architecture
🤜 Skip-connection 사용
- 특징 : paired dataset이 어느 정도 비슷한 컨텐츠들이 있는 경우 skip-connection을 많이 사용하는 경향을 보이고 있다.
- 장점 : 입력 데이터에 대한 detail들이 마지막 layer까지 잘 전달 된다.
- 단점 : skip-connection을 사용해서 detph가 거의 없다. 따라서 생성된 결과가 별로다.
ResNet Architecture (9 layers)
🤜 Residual Block을 사용해 보다 더 효율적으로 Deep하게 쌓을 수 있게 된 네트워크
- 특징 : Depth도 있고 bottleneck도 없어서 detail도 간직하고 생성 결과 퀄리티도 좋은 편이다.
- 단점 : bottleneck이 없어서 많은 메모리를 요구하고 그로 인해 learn of parameter 개수가 적어지게 된다.
🗣 Encoder-Decoder vs U-Net 구조의 특징 및 장단점은 Pix2Pix 리뷰 글에서 확인하실 수 있습니다.
5-2. Discriminator
👉 PatchGAN을 사용 (참고 blog Link)

DCGAN의 Discriminator
이미지 전체를 보고 진짜인지 가짜인지 판별 합니다.
PatchGAN의 Discriminator
이미지 전체에서 Receptive field 크기 만큼 특정 Patch(receptive field) 부분을 보고 그 부분이 진짜인지 가짜인지 판별 합니다..
6. Loss
6-1. GAN이 Training 하기 어려운 이유
Adversarial Loss
→ For the mapping function G : X → Y and its discriminator Dy
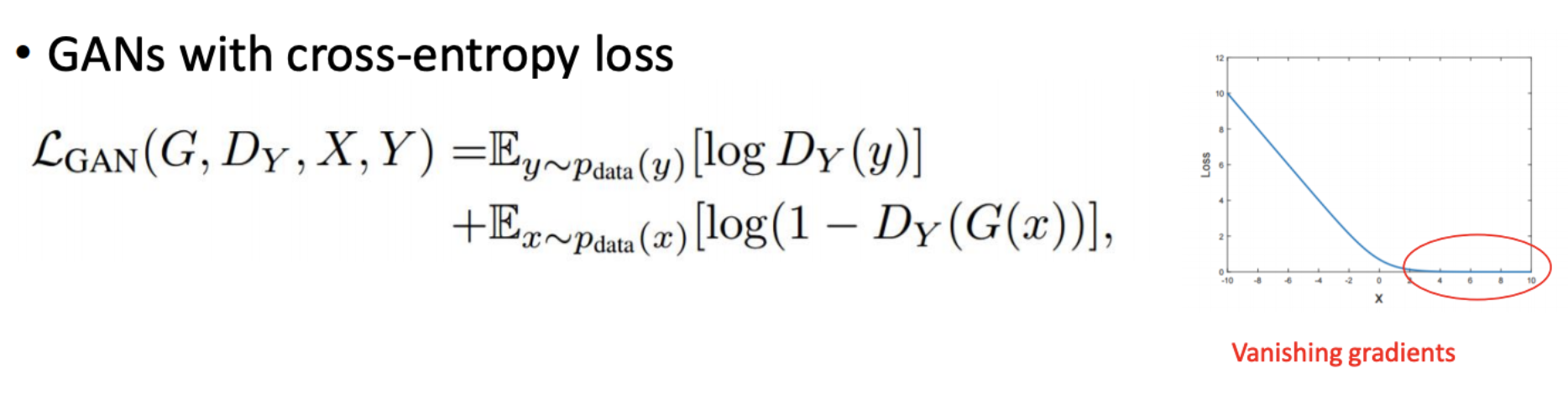
Gradient가 Flatten해지는 현상은 X가 Positive일 때 Flatten해져 loss가 0에 가까워집니다. 그로 인해 Vanishing gradients 현상이 발생되게 됩니다. 그래서 Adversarial loss만 사용하는 일반적인 GAN은 Training하기 어려워집니다.
해결 방법

Discriminator의 역할은 진짜를 진짜라고, 가짜를 가짜라고 잘 맞추는 것 입니다. 그래서 진짜일 경우 1에 가까운 값을 내야하고 가짜일 경우 0에 가까운 값을 내야합니다. LSGAN Loss를 사용하면 Vanishing gradients 문제가 없기 때문에 training이 Adversarial Loss를 사용할 때 보다 훨씬 안정적으로 학습이 진행이 되고 생성된 이미지 퀄리티도 훨씬 좋게 됩니다. 또한 GAN 학습 과정 중 불안정하게 학습되는 대표적인 예시인 Mode Collapsing가 발생한다던지 생성된 이미지에 노이즈가 끼면서 생성이 된다던지 하는 현상이 없습니다.
Mode collapsing
mode collapsing은 training data의 확률 분포를 모두 커버하지 못한 경우 다양성을 잃어버리게 됩니다. 그러면 GAN 학습시 loss만 줄이는 목표를 갖고 학습을 하다보니 Generator가 전체 데이터 분포를 커버하지 못하고 특정 부분의 데이터 분포만 커버하며 학습을 하게 될 수 있습니다. (ex, MNIST에서 4만 계속 생성하는 경우가 발생)
해결방안
- Feature matching: Fake image와 Real image 사이에 Least Square loss function을 사용한다 (LSGAN의 loss)
- mini-batch Discriminator: mini-batch별로 fake image와 real image 사이의 확률분포 거리의 차이를 loss function에 추가해준다.
- Historical averaging: batch 단위로 parameter를 update하면 이전 학습은 잘 잊혀지게 되므로 이전 학습 내용을 기억하는 방식으로 학습을 진행한다.
참고자료: GAN - Ways to improve GAN performance
6-2. L1 Loss
L1 loss는 Ground truth Y와 generation image G(z)의 차이 값에 사용되는 중요한 loss function입니다. 왜냐하면 흔히 minmax game이라고 하는 GAN loss만 이용하면 G와 D가 경쟁을 하며 학습을 하다보니 training이 잘 안되는 경우가 많습니다. 이때 L1 loss를 GAN loss와 함께 사용을 한다면 L1 loss가 GAN이 학습을 할 때 Guide 역할을 해주므로써 길잡이 역할을 해주게 됩니다. 이때 detail한 부분들(이미지를 생성한다거나 선명하게 한다는 부분들)은 GAN loss가 담당을 하게 됩니다.
Pix2Pix에서는 입력 데이터가 어떻게 변경하면 될지 정답이 있는 Paired Image-to-Image translations 입니다. 그래서 L1 loss를 사용해서 흑백 → 컬러로 변경 했을 때 진짜 정답인 target image랑 동일해야 한는 정답이 있습니다.
하지만 CycleGAN은 정답이 없는 Unpaired Image-to-Image translations 입니다. 그래서 관련이 없는 이미지를 막 넣어도 된다는 말 입니다. 대표적인 예시로 말 사진을 넣으면 어떤 결과값을 내놓는지는 잘 모르겠지만 반대 방향인 얼룩말 → 말 로 변경을 해주는 네트워크를 훈련시켜서 얼룩말을 말처럼 만들었을 때 다시 말이 얼룩말로 돌아가야 하는지 정답이 있는 상황으로 학습을 할 수 있다.
6-3. Identity Loss
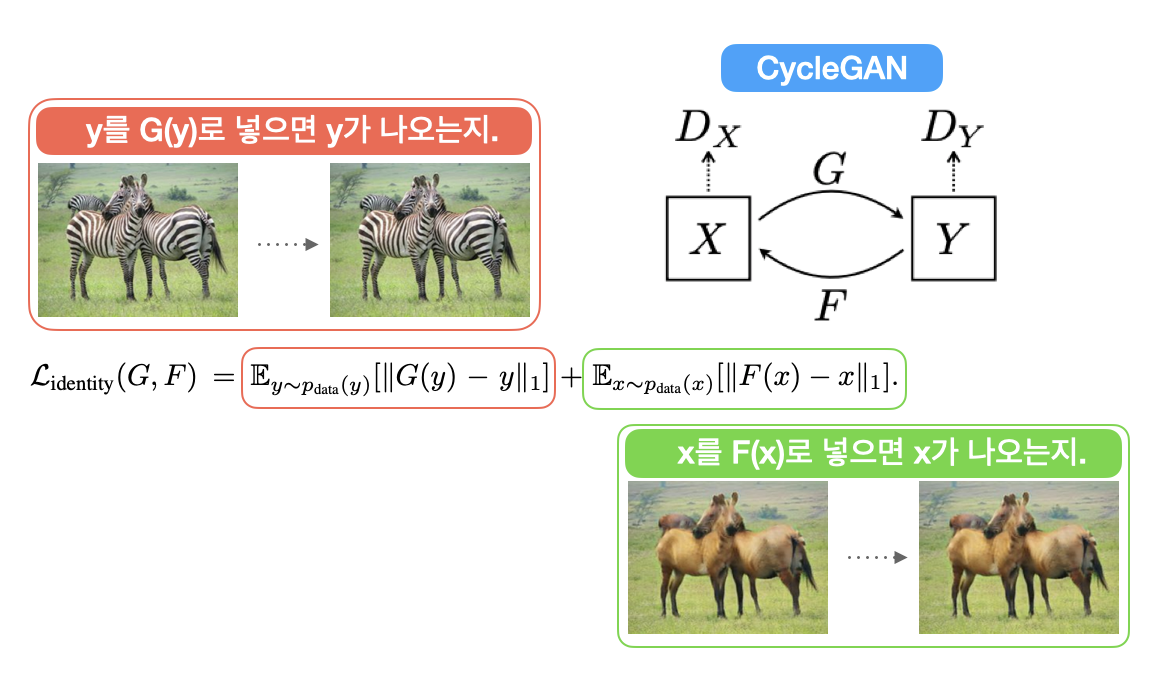
사실 Identity Loss는 써도 그만 안써도 그만 입니다. 다만 좀 더 detail하고 결과물의 quality가 중요하다고 하면 쓰는게 좋습니다. 예를 들자면 모네 그림같은 경우 그 특정 화가의 화풍을 캐치해야하고 명화니깐 이미지 퀄리티도 좋아야 하니 이러한 경우 Identity Loss를 사용합니다.
그럼 간단히 Identity Loss의 장단점에 대해 정리를 해보도록 하겠습니다.
🤜 Identity Loss의 장단점
- 장점 : 생성 결과물의 quality를 중요시 하고 detail한 결과물을 얻고 싶을때 사용하면 좋음.
- 단점 : Parameter 수가 많아져서 연상량이 많아지게 되므로 학습 속도가 느려지게 된다.
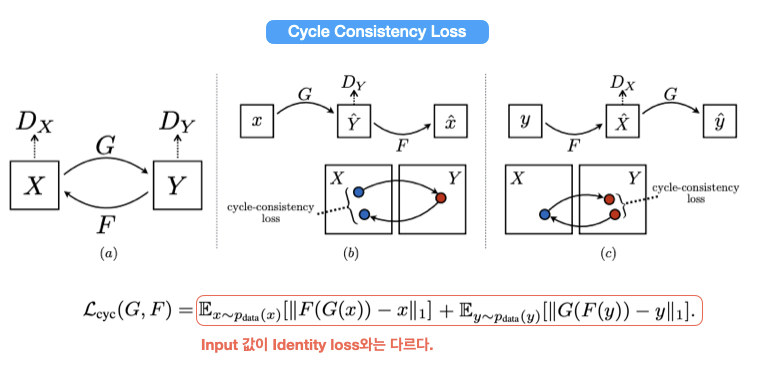
6-4. Cycle Consistency Loss
6-5. Total Loss

7. Details
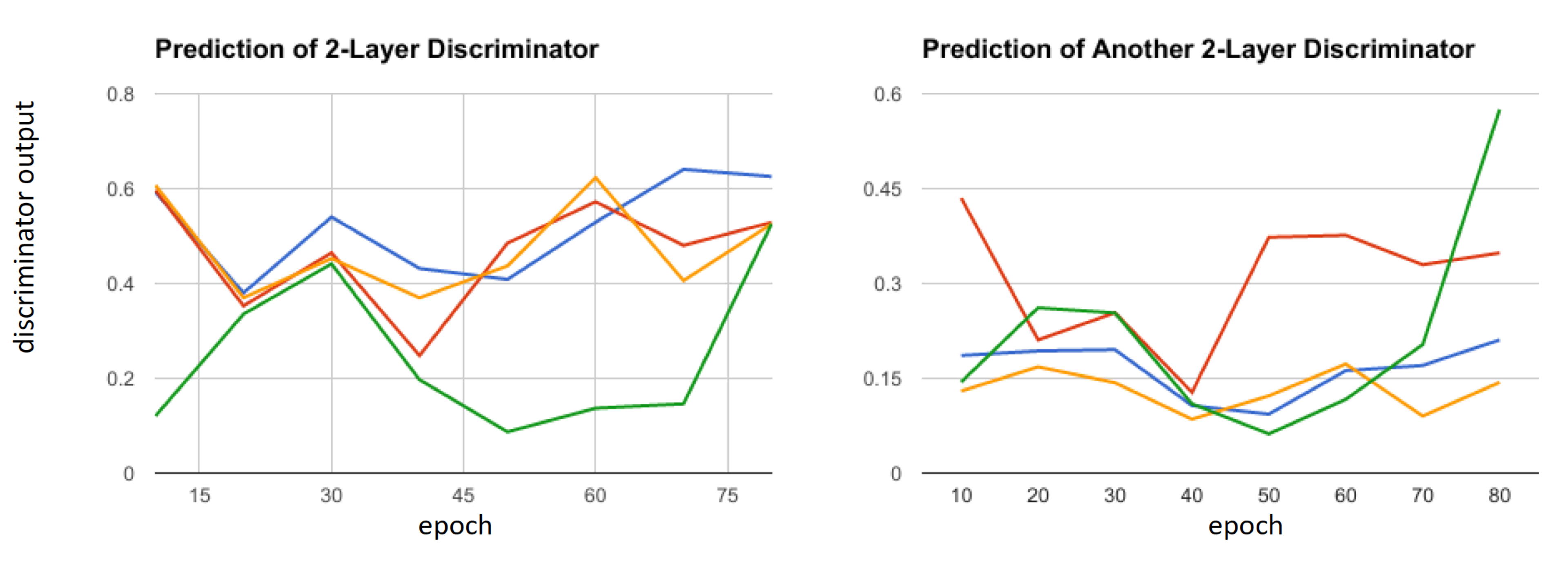
Seed값을 A에서 training한 모델을 두고 Seed값을 B라는 값으로 변경 후 처음부터 다시 학습을 시켜보니 분명 Seed A일때의 Discriminator에서 진짜라고 인식하던 결과물이 Seed B일때는 가짜라고 인식을 해버리는 현상이 발생되게 된다. 즉, Seed 값이 바뀔때 마다 학습이 안정적으로 될 때가 있고 불안정하게 될 때가 있다.
7-1. Solution
🤜 Solution 1 (비추)
- 특징 : Discriminator가 하나가 여러개 모델을 생성한 후 각각 모델에서 나온 값을 평균 내어서 하나의 Generator에 보여주는 방법.
- 장점 : Seed 값이 바껴도 학습이 안정적으로 진행.
- 단점 : Discriminator 개수가 많아지다보니 메모리를 많이 소모.
🤜 Solution 2 (강추)
- 특징 : Reinforcement learning(강화학습)에서 사용하는 방법 중 Replay buffer 방법을 사용. [참고 Link]
→ Generator가 만들어준 사진들을 Discriminator에 주기적으로 보여주는 방법입니다. 그러면 과거의 Generator가 지금까지 어떻게 행동했는지 Discriminator가 대응을 해야하기 때문에 훨씬 안정적으로 학습이 이루어지게 됩니다.
→ Discriminator에 주기적으로 생성된 이미지를 보여줄때는 Generator는 Backpropagation 과정은 이루어지지 않고 Discriminator만 이루어 집니다. 그래서 Discriminator가 가짜를 더 잘 구분할 수 있도록 합니다.
- 장점 : 학습이 안정적으로 진행.
⭐️ 다르게 생각을 해보면 Generator를 여러개 늘리는 방법이라고도 볼 수 있을거 같습니다.
Reference
✔️ Pix2Pix paper [Link]
✔️ PatchGAN Discriminator 뽀개기 [Link]
✔️ Receptive Field Wikipedia [Link]
✔️ CycleGAN D2 youtube [Link]
✔️ CycleGAN paper [Link]
✔️ Patch GAN Discriminator Issue [Link]
✔️ Reinforcement learning Replay buffer [Link]
✔️ GAN - Ways to improve GAN performance [Link]



