
티스토리 뷰
신경망 학습의 전체 그림
1단계) 미니배치(Mini-Batch)
training data중 일부를 가지고 와서 배치화 시키는 작업이다. 미니배치의 목표는, 손실함수(cost function = loss function)값을 줄이는 것이 목표이다.
2단계) 기울기 산출
미니배치의 cost function 값을 줄이기 위해 각 가중치 매개변수(weight)의 기울기를 구한다. 기울기는, cost function의 값을 가장 작게 하는 방향을 제시하는 역할.
3단계) 매개변수 갱신
weight를 기울기 방향으로 아주 조금씩 갱신해준다.
4단계) 반복
1 ~ 3단계 과정을 계속 반복한다.
여기까지는 '밑바닥부터 시작하는 딥러닝'에 대한 내용을 작성한 것 입니다.
이제부턴 연구실에서 책 세미나 한 내용을 다시 혼자 정리한 내용을 적도록 하겠습니다.
1. 신경망(Neural Network) 학습
어떤 책에선 신경망을 Artificial Neural Network라 적었지만 저는 넒은 의미로 보기 위해서 Neural Network라 적도록 하겠습니다.
목표 : Cost function(=loss function)의 값을 가장 작게 만드는 Weight값을 찾는것을 목표로 한다.
* 찾는 방법은 정말 많지만, 여기서는 기본적인 방법인 Gradient Descent로 구현을 하도록 하겠습니다.
신경망은 end-to-end이다. 주어진 데이터를 신경망 스스로 문제의 패턴을 발견하려고 한다. 따라서 신경망은 사람의 개입이 아예 없이 오로지 스스로 특징(Feature)를 찾아 낸다.
2. 데이터를 구분하는 이유(test vs train vs validation)
기계학습의 최종 목표 : 범용능력
※범용 능력이란, 어떠한 데이터가 들어와도 그 데이터들에 대해서 잘 처리하는 능력을 의미한다.(범용적인 능력)
--> 범용 능력은 Overfitting 상태를 피하는 것이다.
Overfitting이란?
특정 데이터에 너무 Fitting하게 학습이 되어서 수중에 있는 데이터셋을 잘 맞추더라도, 다른 데이터셋일 들어오면 엉망이 되버린다. 따라서 Overfitting을 피하는게 기계학습의 목표고 그것이 범용능력을 키우는 것이다.
-
훈련 데이터(training dataset) : Training data만을 이용해서 최적의 매개변수(Weight)를 찾는다.
-
테스트 데이터(test dataset) : 훈련한 모델이 잘 훈련이 되어있는지 실력을 평가할때 사용한다.
-
검증 데이터(Validation dataset) : 적절한 Hyperparameter를 구하기 위한 데이터이다.(학습 과정에서 적절한 하이퍼파라미터를 다 구했으면 이 데이터를 training data로 합친 후 다시 학습을 진행한다. 그 이유는, dataset이 없어 죽겠는데 적절한 Hyperparameter가지 다 구했으니 Validation dataset을 버리느니 차라리 training data로 가지고 와서 더 많은 training data로 학습을 시키는기 더 나은 방법이니까)

정리
Training dataset으로만 학습을 시킨다.(이때 Validation과 Test dataset은 사용 안한다.
학습 시킨 모델이 적합한지 판별하기 위해서 Validation dataset으로 검증을 하게 된다.
검증을 하는 이유는, Validation dataaset의 목적이 Hyperparameter값이 적절한지 정하는 Dataset이기 때문이다. 최종적으로 검증이 되었으면 Validation dataset을 training dataset으로 합친 후 학습을 진행한다.
3. 손실함수(Loss function = Cost function)
*저는 여기서 비용함수(Cost function)이라고 칭하도록 하겠습니다.
Cost Funcdtion은, 신경망 성능의 '나쁨'을 나타내는 지표이다. 즉, 얼마나 훈련 데이터를 잘 처리 못하는지를 나타낸다. 많은 손실함수가 존재하지만, 가장 기본적이고 가장 대표적인 방법 두가지만 소개를 하도록 하겠습니다.
1) 평균제곱오자(Mean Squared Error; MSE)
* 일반적으로 task는 Regression, activation function은 Identity function을 사용한다고 한다.

Q1. 왜 Regression을 할때 activation function을 Softmax function이 아닌 Identity function을 사용하는가?
R1. 회귀(Regression)라는 문제(task)란, 입력데이터에서 연속적인 수치를 예측하는 문제를 의미한다. 예를 들면 사람의 나이를 나타낼 수 있다. 따라서 이는 Softmax와 Sigmoid처럼 출력 값의 범위가 정해져 있는게 아니다. 만약 range가 정해져 있으면, Regression을 할 수 없다. 따라서, 마지막 출력레이어에 Activation Function을 Identity Function(항등함수)을 사용해야 각 Hidden node들의 출력값들을 그대로 반영이 된다. 출력값이 그대로 반영된 값인 yk(신경망이 추정한 값), 정답값인(target value) tk랑 비교해서 오차를 계산하고, 그 오차(error)가 줄어들게끔 학습을 시켜야 한다.
② 기울기를 왜 구하는가?
Cost Function에서 오차(error)가 가장 작은 지점을 구하기 위해서이다. 이 과정은 최소점을 찾는 과정이다.
③ 그러면 왜 Cost Function에서는 Convex 형태를 지향하는가?
Cost Functioni에서 error가 최저인 지점을 찾아야하는데 Convex 형태(U자 모양)가 error가 최소인 지점을 찾기 가장 적합하기 때문에 Cost Function을 선택하고 또는 새로 만들때 Convex 형태가 되도록 생각을 하며 설계를 하는게 좋다.
위에서 왜 Square error를 사용하고 왜 Convex 형태인 모양을 지향하는지 알아보았다. 그러면 최종적으로 MSE(Mean Squared Error)가 왜 등장하게 되었는지 과정을 통해 알아보도록 하겠습니다.
※ MSE가 등장하게 된 이유
① 딥러닝을 통해 딥러닝 모델을 만든다
하이퍼파라미터를 설정하겠다는 것이다.
② 하이퍼 파라미터를 설정하기 위한 방법
데이터를 가지고 파라미터를 설정하기 위해 Cost Function을 저의하고, 이것을 정답값(tk)과 예측값(yk)에 대한 오차를 줄여나가는 방향으로 학습을 할 때, 그대 파라미터를 결정하게 된다. 이때 Cost Function에서 최저점을 나타내는 파라미터가 최적화 되는 것이고 개발자는 최저점이 되는 지점일때의 하이퍼파라미터를 가지고 학습을 시키면 된다.
③ Gradient Descent는 언제 사용하는가?
Cost Function에서 최저점을 나타내는 값을 찾기 위한 과정 중, 해당 본문에서는 Gradient Descent를 사용하게 된다. 이는, 함수가 Convex형태가 되었을 때 error가 최저점일때(Cost or loss 값이 최저점일때)를 찾기 쉬우므로 'Cost Function 형태가 기본적으로 Convex한 형태를 띄우는 것이다.' 그래서 MSE방식이 나온것이다.
그러면 여기서 궁금한점이 생길것이다.
Q3. CEE는 Squared Error 방식이 아니니까 Convex한 형태가 아닌것인가??
R3. CEE는 이제부터 알아볼 것이지만, 그래프 형태가 log함수이다. 그리고 우선적으로 생각을 해야할 점이, Cost Function의 가장 이상적인 형태가 Convex 형태를 띄우는 것을 먼저 생각해야한다. 그러나 실제 사용을 해보면 완벽하게 Convex형태로 안나오고 울툴불퉁한 형태가 나오는게 대부분이다. 그래서 Cost Function을 선택해서 사용을 할때 위에서도 이야기를 햇지만, Cost Function 형태가 Convex 한 방향으로 생각을 하면서 모델을 구성해야한다.
2) 교차 엔트로피 오차(Cross Entropy Error;CEE)
*일반적으로 task는 Classification, activation function은 softmax일때 사용을 한다.


Q1. 신경망의 출력이 Softmax를 사용한 값인데, Softmax는 언제 사용하고 어떤 task일때 사용되는가?
R1. Multi class에 대한 Classification에 사용된다.(Multi Classification)
Q2. 왜 Softmax를 사용하는가?
R2. Q1에서 Multi Classification 문제일때 사용이 된다고 언급했다. softmax는 class들 간의 배반적인 성격때문에 사용을 한다. 예를 들자면 동물의 종류가 고양이, 강아지, 다람쥐가 있다고 하자. "A라는 동물은 고양이이면서 다람쥐이다"라는 결과값이 나오는 분류가 싫어서 Softmax를 사용하는 것이다. 만약 Sigmoid로 사용하게 된다면(Sigmoid의 range는 0 ~ 1이다.) 모든 클래스에 대해 배반적응로 나오는게 아니라 독립적으로 나오니까 안된다.
*softmax의 결과값은 확률로 사용될 수 있으며, 모든 결과값의 합이 1이므로 가장 큰 값 하나만 신경쓰면 된다.
4. 경사하강법(Gradient Descent)
*경사 상승법과 경사 하강법을 통틀어서 경사법이라고 하지만. 딥러닝 분야에선 경사하강법으로 등장할때가 많으니 여기서도 경사하강법으로 사용하겟습니다.(어짜피 부호만 반전시켜주면 같은 상황입니다.)
결론부터 말하자면, 경사하강법은 Cost Function을 최소화하기 위해 반복해서 파라미터 값들을 조정해 가는 방법이다.
경사하강법을 이해하려면 우선 신경망(Neural Network)을 왜 사용하는지 알아야합니다. 맨 위에서도 설명을 했지만 다시 한번 설명을 하도록 하겠습니다.
Neural Network를 사용하는 이유는 Decision boundary과 Surface를 만들기 위함입니다. 이것들을 만드는 구성 요소들은 weight와 bias입니다. neural networ는 해당 매개변수들을 스스로 찾기 때문에 신경망을 쓰는 것 입니다.
경사하강법을 수식으로 나타내면 다음과 같습니다.


위 수식의 의미는 어떻게 weight를 업데이트 시키는지 말하는것이다.
현재 그래프에서 weight의 점이 찍혓다고 생각하자. 수식은, 이 weight를 기점으로 얼마만큼의 간격으로 더 나아가서 weight를 진행시킬것인지 말하는 거다.
이 얼마만큼을 어떻게 진행시킬 것인지는 '크기와 방향'이다. Learning rate가 얼마나 진행시킬것인지의 크기를 말하는 거고, learning rate에 곱해진 편미분과 -는 weight가 어느 방향으로 갈 것인지를 말해주는 방향을 의미한다.
Gradient Descent는 Global Minima를 찾기 위해 현재 내가 있는 weight state에서 다음 state로 어느 방향으로 얼만큼 진행할 것인가를 정하는 것이다.--> 어떤 식으로 update 시킬것인가를 의미.
Gradient Descent에도 문제점이 있다. 바로 Hyperparameter인 Learning rate를 어떻게 정해주는지에 따라서 학습의 성공을 좌지우지한다.
1) Learning rate가 너무 작을 경우

Learning rate가 작을 경우 Global Minimum에 가는 과정이 시간이 오래걸리고 반복을 많이 진행해야하는 단점이 있다. 그리고 더 중요한 이유는,

learning rate가 작다보니 앞으로 나아가는 크기(step)이 작아서 local minima에 빠지기 쉬우며 더 좋은 해가 있어도 그 해를 못찾게 된다.
2) Learning rate가 클 경우
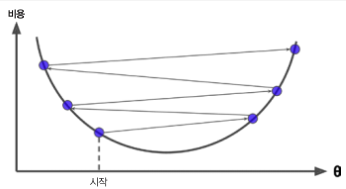
골짜기를 가로질러서 반대편으로 건너갈 수 있을 뿐더러 더 높은곳으로 올라가는 over shutting 현상이 발생할 수 있다.
3) 평탄한 지역
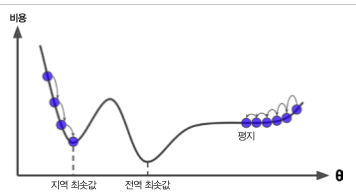
평탄한 지역을 벗어나기 위해 시간도 오래 걸리고 일찍 멈추게 되는 현상이 발새오디게 된다.
local minima에 빠진 경우, 탈출하는 방법은 여기에선 learning rate를 설정하는 방법을 사용하지만, 다음 포스팅에서 설명할 모멘텀이라는 방법도 있다. 간단하게 모멘텀에 대해 설명을 하자면
모멘텀은, 관성이라는 뜻을 의미하며, 이전에 얼만큼 진행힜는지 기억하고 있고, 다음번 update에 그 기억한 것을 반영한다. 따라서 평탄한 평지형태일때 벗어나고 싶을때 모멘텀을 사용하면 좋다.
5. 배치와 미니배치(Gradient Descent)
1) 배치와 미니배치와 stochastic 개념이 나온 배경.
Batch Gradient Descent
가지고 있는 training data를 한꺼번에 배치화 시켜서 넣고, 평균적인 경향을 반영해 파라미터들을 업데이트하고 싶지만, 메모리가 한정적이다보니 쪼개서 넣을 방법을 생각해보다가 미니배치라는 개념이 나온것이다.

mini-batch Gradient Descnt
Random하게 Batch size 데이터 만큼 데이터를 선정 후 training data를 학습을 키고 각 미니배치마다 나온 Cost Function의 합을 구해서 평균을 낸다.(따라서 미니배치가 너무 작으면 지그재그 현상이 발생되게 된다.)

Stochastic Gradient Descent
* 다음 포스팅에서 SGD에 대한 개념을 자세하게 적도록 하겠습니다.
batch-size의 크기가 1인 경우이다.
하나의 샘플을 무작위로 선택하고 그 하나의 샘플에 대한 Gradient를 계산하는 방법이다.

Q. 배치로 해서 훈련을 시키는게 가장 좋은방법인거 같은데 왜 미니배치와 stochastic라는 개념이 나왓나?
가장 좋은 방법은, Batch화 시키서 학습을 하는게 가장 좋은방법이지만, 메모리 문제도 있고, 더 중요한 문제는 Speed에 대한 문제이다.(Batch는 한번 다 보고 한번 update하는 과정을 반복하다보니 training 속도가 느리다.) 사람들은 더 빠르고 더 효과적이고 더 편리한 알고리즘을 쓰길 원한다. 그래서 배치로 하면 training 속도가 느려지니까 배치 다음으로 생각을 한게 Stochastic이다. 해당 경사 하강법의 실질적인 의미는 "가지고 있는 샘플중에서 무작위로 뽑은 것"이라고 생각하면 된다.
*무작위로 뽑은것은 그 데이터 중에서 대표라고 생각 하면 된다.
미니배치는 예를 들어서 100만개 중에서 100개를 랜덤하게 뽑으면 100개가 전체 데이터의 대표라고 생각을 한다.
*임의적으로 랜덤하게 뽑는다는 것은, 샘플링 한다는 것이다. 샘플링 한다는 것은 그 데이터에서 대표하는 의미이며 랜덤하게 뽑은다는것은 모든 class를 다 골고루 뽑은거랑 같은 의미이다.
'Python > 머신러닝&딥러닝' 카테고리의 다른 글
| [Kaggle] Attention on Pretrained-VGG16 for Bone Age_전처리 과정 (1) | 2019.05.19 |
|---|---|
| 딥러닝 필수 기본 개념 (0) | 2019.05.19 |
| Ch02. 퍼셉트론(밑바닥부터 시작하는 딥러닝) (1) | 2019.04.12 |
| [실습]언어구분학습_1 (0) | 2018.02.18 |
| [실습] 붓꽃 품종 분류를 해보자 (0) | 2018.02.11 |


